
lucene

文章目录
lucene
使用普通数据库的缺陷
-
因为没有通过高效的索引方式,所以查询的速度在大量数据的情况下是很慢。
-
搜索效果比较差,只能对用户输入的完整关键字首尾位进行模糊匹配。用户搜索的结果误多输入一个字符,可能就导致查询出的结果远离用户的预期。
lucene 和 es的关系
Lucene:底层的API,工具包
Solr:基于Lucene开发的企业级的搜索引擎产品
Elasticsearch:基于Lucene开发的企业级的搜索引擎产品
数据查询的常用手法
- 顺序扫描法
- 倒排索引法
-
顺序扫描法,查询准确率高,但是随着查询数据量变大,越来越慢,例如 数据库
like模糊查询, 文本编辑器 ctrl + f 查询功能,缺点: ==数据量越大,查询速度越慢== -
倒排索引法, 提取关键词,建立索引(目录), 通过索引目录辅助查找资源的位置 ,==查询速度快,不会因为数据量增加使速度变慢==, 缺点:索引文件占用额外磁盘空间,磁盘占用会增大 【空间换时间】
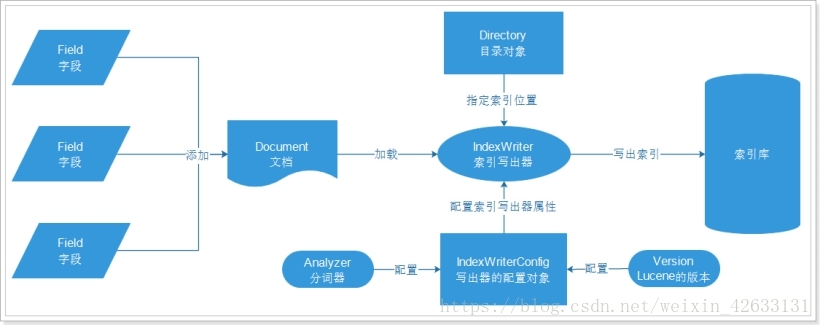
lucene 接口中的概念
3种类型
- 是否分析
- 是否索引
- 是否存储
| Field类 | 数据类型 | Analyzed 是否分析 | Indexed 是否索引 | Stored 是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等) 是否存储在文档中用Store.YES或Store.NO决定 |
| LongField(FieldName, FieldValue,Store.YES) | Long型 | Y | Y | Y或N | 这个Field用来构建一个Long数字型Field,进行分析和索引,比如(价格) 是否存储在文档中用Store.YES或Store.NO决定 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | N | N | Y | 这个Field用来构建不同类型Field 不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader) | 字符串 或 流 | Y | Y | Y或N | 如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
查询的分类
| 名字 | 解释 |
|---|---|
| MathAllDocsQuery | 使用MatchAllDocsQuery查询索引目录中的所有文档 |
| TermQuery(精准查询) | 通过项查询,TermQuery不使用分析器所以建议匹配不分词的Field域查询,比如订单号、分类ID号等 |
| NumericRangeQuery | 可以根据数值范围查询。 |
| BooleanQuery | 可以组合查询条件。 |
查询接口
| 方法 | 说明 |
|---|---|
| indexSearcher.search(query, n) | 根据Query搜索,返回评分最高的n条记录 |
| indexSearcher.search(query, filter, n) | 根据Query搜索,添加过滤策略,返回评分最高的n条记录 |
| indexSearcher.search(query, n, sort) | 根据Query搜索,添加排序策略,返回评分最高的n条记录 |
| indexSearcher.search(booleanQuery, filter, n, sort) | 根据Query搜索,添加过滤策略,添加排序策略,返回评分最高的n条记录 |
其他补充
[[post/14.新语言学习记录/语言技术/Golang/理论学习/实习学习/elasticsearch | es笔记]]
文章作者 lyr
上次更新 2022-05-05