apache_kafaka原理

文章目录
Kafka如何实现高性能IO?
总结
- 批量消息提升服务器处理能力【buffer缓存】
使用批量消息提升服务端处理能力
我们知道,批量处理是一种非常有效的提升系统吞吐量的方法。在 Kafka 内部,消息都是以“批”为单位处理的。一批消息从发送端到接收端,是如何在 Kafka 中流转的呢?
使用顺序读写提升磁盘 IO 性能
对于磁盘来说,它有一个特性,就是顺序读写的性能要远远好于随机读写。在 SSD(固态硬盘)上,顺序读写的性能要比随机读写快几倍,如果是机械硬盘,这个差距会达到几十倍。为什么呢?
操作系统每次从磁盘读写数据的时候,需要先寻址,也就是先要找到数据在磁盘上的物理位置,然后再进行数据读写。如果是机械硬盘,这个寻址需要比较长的时间,因为它要移动磁头,这是个机械运动,机械硬盘工作的时候会发出咔咔的声音,就是移动磁头发出的声音。
顺序读写相比随机读写省去了大部分的寻址时间,它只要寻址一次,就可以连续地读写下去,所以说,性能要比随机读写要好很多。
Kafka 就是充分利用了磁盘的这个特性。它的存储设计非常简单,对于每个分区,它把从 Producer 收到的消息,顺序地写入对应的 log 文件中,一个文件写满了,就开启一个新的文件这样顺序写下去。消费的时候,也是从某个全局的位置开始,也就是某一个 log 文件中的某个位置开始,顺序地把消息读出来。
这样一个简单的设计,充分利用了顺序读写这个特性,极大提升了 Kafka 在使用磁盘时的 IO 性能。
数据库自增主键原理
自增主键就是顺序读写,uuid 随机读写速度太慢了
利用 PageCache 加速消息读写
概念理解
操作系统 之前学的什么缺页中断,其实就是 pageCache,这里直接讲pageCache 了
在 Kafka 中,它会利用 PageCache 加速消息读写。PageCache 是现代操作系统都具有的一项基本特性。通俗地说,PageCache 就是操作系统在内存中给磁盘上的文件建立的缓存。无论我们使用什么语言编写的程序,在调用系统的 API 读写文件的时候,并不会直接去读写磁盘上的文件,应用程序实际操作的都是 PageCache,也就是文件在内存中缓存的副本。
应用程序在写入文件的时候,操作系统会先把数据写入到内存中的 PageCache,然后再一批一批地写到磁盘上。读取文件的时候,也是从 PageCache 中来读取数据,这时候会出现两种可能情况。
一种是 PageCache 中有数据,那就直接读取,这样就节省了从磁盘上读取数据的时间;另一种情况是,PageCache 中没有数据,这时候操作系统会引发一个缺页中断,应用程序的读取线程会被阻塞,操作系统把数据从文件中复制到 PageCache 中,然后应用程序再从 PageCache 中继续把数据读出来,这时会真正读一次磁盘上的文件,这个读的过程就会比较慢。
用户的应用程序在使用完某块 PageCache 后,操作系统并不会立刻就清除这个 PageCache,而是尽可能地利用空闲的物理内存保存这些 PageCache,除非系统内存不够用,操作系统才会清理掉一部分 PageCache。清理的策略一般是 LRU 或它的变种算法,这个算法我们不展开讲,它保留 PageCache 的逻辑是:优先保留最近一段时间最常使用的那些 PageCache。
Kafka 在读写消息文件的时候,充分利用了 PageCache 的特性。一般来说,消息刚刚写入到服务端就会被消费,按照 LRU 的“优先清除最近最少使用的页”这种策略,读取的时候,对于这种刚刚写入的 PageCache,命中的几率会非常高。
零拷贝原理
Kafka 的服务端在消费过程中,还使用了一种“零拷贝”的操作系统特性来进一步提升消费的性能。
我们知道,在服务端,处理消费的大致逻辑是这样的:
- 首先,从文件中找到消息数据,读到内存中;
- 然后,把消息通过网络发给客户端。
这个过程中,数据实际上做了 2 次或者 3 次复制:
- 从文件复制数据到 PageCache 中,如果命中 PageCache,这一步可以省掉;
- 从 PageCache 复制到应用程序的内存空间中,也就是我们可以操作的对象所在的内存;
- 从应用程序的内存空间复制到 Socket 的缓冲区,这个过程就是我们调用网络应用框架的 API 发送数据的过程。
其他笔记
[[post/14.新语言学习记录/linux/linux基础原理杂记/IO方面的知识|io知识]]
[[post/11.个人总结/中间件/消息队列/消息队列_业务_不丢消息解决 | 消息队列丢消息解决]]
[[post/11.个人总结/中间件/消息队列/消息队列_业务_分布式事务|分布式事务]]
kafka架构
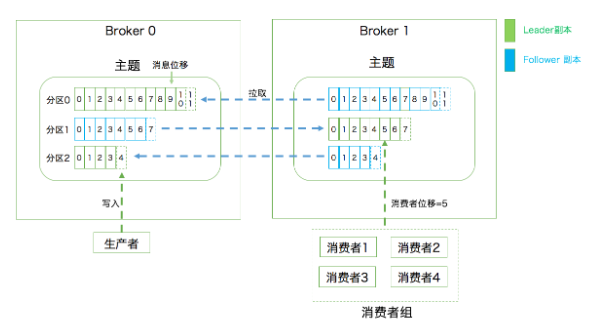
Kafka 属于分布式的消息引擎系统,它的主要功能是提供一套完备 的消息发布与订阅解决方案。在 Kafka 中,发布订阅的对象是主题(Topic),你可以为每 个业务、每个应用甚至是每类数据都创建专属的主题。 Kafka 的服务器端由被称为 Broker 的服务进程构成,即一 个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及 对消息进行持久化。虽然多个 Broker 进程能够运行在同一台机器上,但更常见的做法是将 不同的 Broker 分散运行在不同的机器上,这样如果集群中某一台机器宕机,即使在它上面 运行的所有 Broker 进程都挂掉了,其他机器上的 Broker 也依然能够对外提供服务。这其 实就是 Kafka 提供高可用的手段之一
实现高可用的另一个手段就是备份机制(Replication)。备份的思想很简单,就是把相同 的数据拷贝到多台机器上,而这些相同的数据拷贝在 Kafka 中被称为副本(Replica)
Kafka Broker 是如何持久化数据的。总的来说,Kafka 使用 消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消 息的物理文件。因为只能追加写入,故避免了缓慢的随机 I/O 操作,改为性能较好的顺序 I/O 写操作,这也是实现 Kafka 高吞吐量特性的一个重要手段。不过如果你不停地向一个 日志写入消息,最终也会耗尽所有的磁盘空间,因此 Kafka 必然要定期地删除消息以回收 磁盘。怎么删除呢?简单来说就是通过日志段(Log Segment)机制。在 Kafka 底层,一 个日志又近一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日 志段后,Kafka 会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka 在后台还 有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。 这里再重点说说消费者。在专栏的第一期中我提到过两种消息模型,即点对点模型(Peer to Peer,P2P)和发布订阅模型。这里面的点对点指的是同一条消息只能被下游的一个消 第一层是主题层,每个主题可以配置 M 个分区,而每个分区又可以配置 N 个副本。 第二层是分区层,每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务; 其他 N-1 个副本是追随者副本,只是提供数据冗余之用。 第三层是消息层,分区中包含若干条消息,每条消息的位移从 0 开始,依次递增。 最后,客户端程序只能与分区的领导者副本进行交互。
|
|

https://xstarcd.github.io/wiki/Cloud/kafka_Working_Principles.html
kafka工作原理
目录 http://www.aboutyun.com/thread-11895-1-1.html kafka入门:简介、使用场景、设计原理、主要配置及集群搭建(转): http://www.cnblogs.com/likehua/p/3999538.html apache kafka系列之在zookeeper中存储结构: http://blog.csdn.net/strawbingo/article/details/45484139 Kafka文件存储机制那些事: http://www.open-open.com/lib/view/open1421150566328.html apache kafka系列之server.properties配置文件参数说明: http://blog.csdn.net/lizhitao/article/details/25667831 kafka入门: http://bit1129.iteye.com/blog/2174791 Kafka 设计与原理详解: http://blog.csdn.net/suifeng3051/article/details/48053965
文章作者 LYR
上次更新 2021-08-17