计算机网络八股文
 次阅读
次阅读
文章目录
TCP 相关
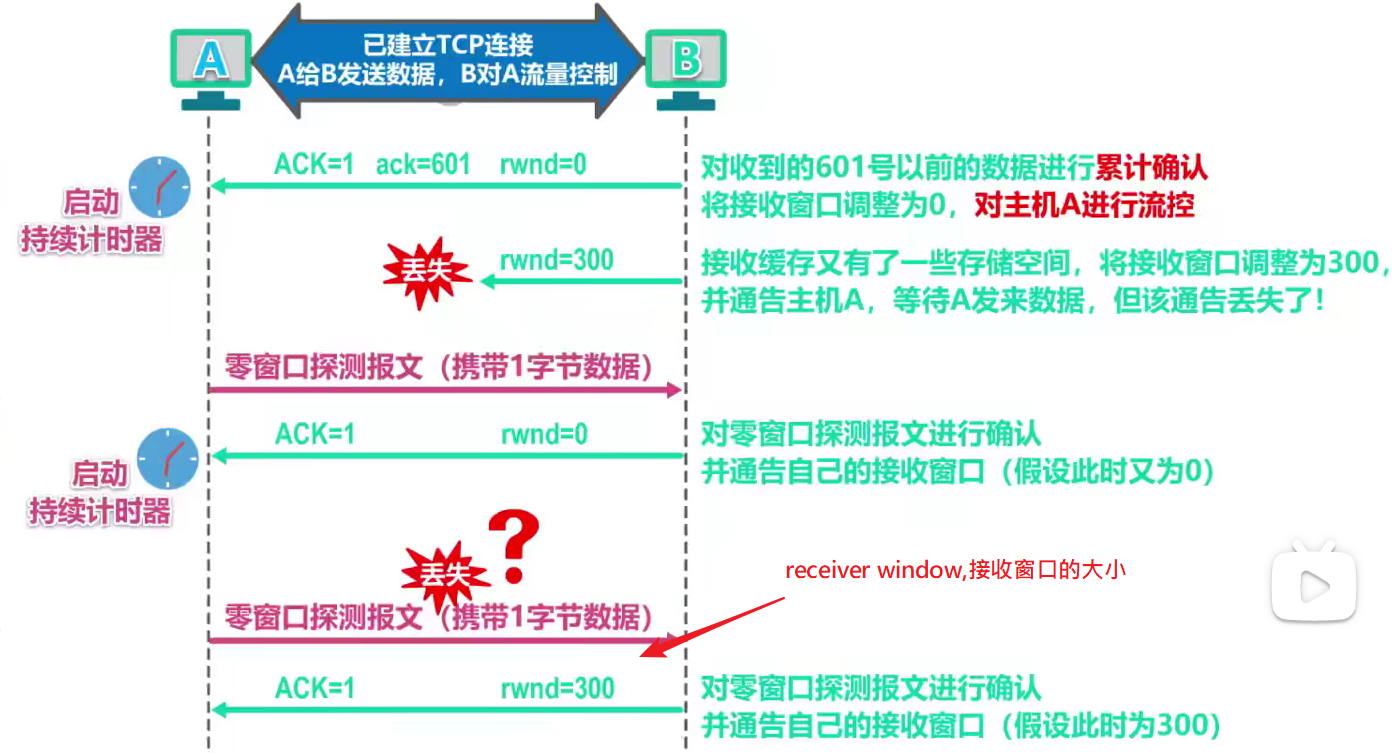
TCP 流量控制
建立连接 会有 syn + ack 机制, 表示 建立连接和 接收成功
发送数据会有 seq+ ACK 机制, 表示发送数据包的序列化 还有对应的应答
公式:
$ TCP发送窗口= min{自身拥塞窗口,TCP接收方的接受窗口} $
TCP拥塞控制
拥塞控制和流量控制的区别
- 拥塞控制 是 对于路由器而言的 【路由器资源不足,就会丢包】
- 流量控制是对于那个接收方而言的 【接收方资源不足】
实际上,拥塞控制主要有这几种常用算法
- 慢启动
- 拥塞避免
- 拥塞发生
- 快速恢复
相关概念: 拥塞窗口 $cwnd$
-
拥塞窗口$cwnd$ 维护原则: 网络没有拥塞 ,拥塞窗口就加大一点,出现拥塞,窗口就减少一点
-
判断网络拥塞的方法:
- 没有按时收到应当到达的确认报文(发生了超时重传)
- 3次重复确认
-
发送方将拥塞窗口作为发送窗口 swnd,即 $swnd = cwnd$
-
维护一个慢开始门限 $ssthresh$ 状态变量
- 当 $cwnd < ssthresh $ 时,使用慢开始算法 【二次方增长】
- 当 $cwnd > ssthresh $ 时,停止使用慢开始,改用拥塞避免算法 【直线上升】
- 当 $ cwnd = ssthresh $, 可以用慢开始 或者 拥塞避免 多种算法
-
TCP Reno版本:
- 快重传,快恢复实现原理
- 个别报文段在网络丢失,但是不一定是因为拥塞
- 发送方误认为拥塞,使用了慢开始,效率太低了
- 判断方法:
- 接收方收不到发送方的正确数据,会返回上一个收到的 ACK 序号 来确认
- 发送方收到连续3次重复确认,才是真正的r认为是发生了拥塞
- 判断方法:
- 快重传,快恢复实现原理
TCP 超时重传的问题
-
往返时间 $RTT $ 如何进行考虑呢? 学习视频
-
rfc6298 建议的超时重传时间RTO:
- $RTO = RTT_s + 4*RTT_D$
-
其他问题: 无法正确策略RTT 的时间,因为无法区分是重传报文段 还是 原报文段的响应
-
karn 算法解决思路: 遇到重传,就不计入 RTT 样本
-
对 karn 算法的修正: 报文段每重传一次,就把超时重传时间RTO 加大一点,典型做法是 $RTO_新 = RTO_旧 * 2$
TCP 首部字段
- tcp报文由首部和数据载荷两部分构成
- TCP的全部功能都体现在它首部中各字段的作用
常见标志位:
-
RST , 表示tcp异常,必须释放连接, 取值0 or 1
-
ACK , 报文确认 取值 0 or 1
-
PSH, 推送操作,取值为 1 会尽快交给上层应用,不必等待接收缓存都满了再 向上交付
-
FIN, 表示断开连接
-
URG, 紧急指针
-
选项(长度可变)
- 最大报文长度$MSS$ 选项: TCP 报文段数据载荷部分最大长度
- 窗口扩大选项: 为扩大窗口(提高吞吐率)
- 时间戳选项:
- 计算往返时间 $RTT $
- 用于处理序号超范围情况,称为防止序号绕回 $PAWS $
最长前缀匹配原则
IP 匹配转发 使用最长前缀匹配原则,转发数据包
动态路由选择
路由器通过路由选择协议,自动获取路由
- 静态路由选择: 人工配置简单,开销小,不能及时适应网络 流量 拓扑变化
- 动态: 开销大,复杂,较好的适应网络状态变化
-
路由选择协议:
-
内部网络协议 IGP
- 路由信息 RIP
- 内部网络路由 IGRP
- 开放式最短路径优先 OSPF
-
外部网关协议 EGP
- 边界网关协议 BGP
-
随机接入协议 CSMA/CA
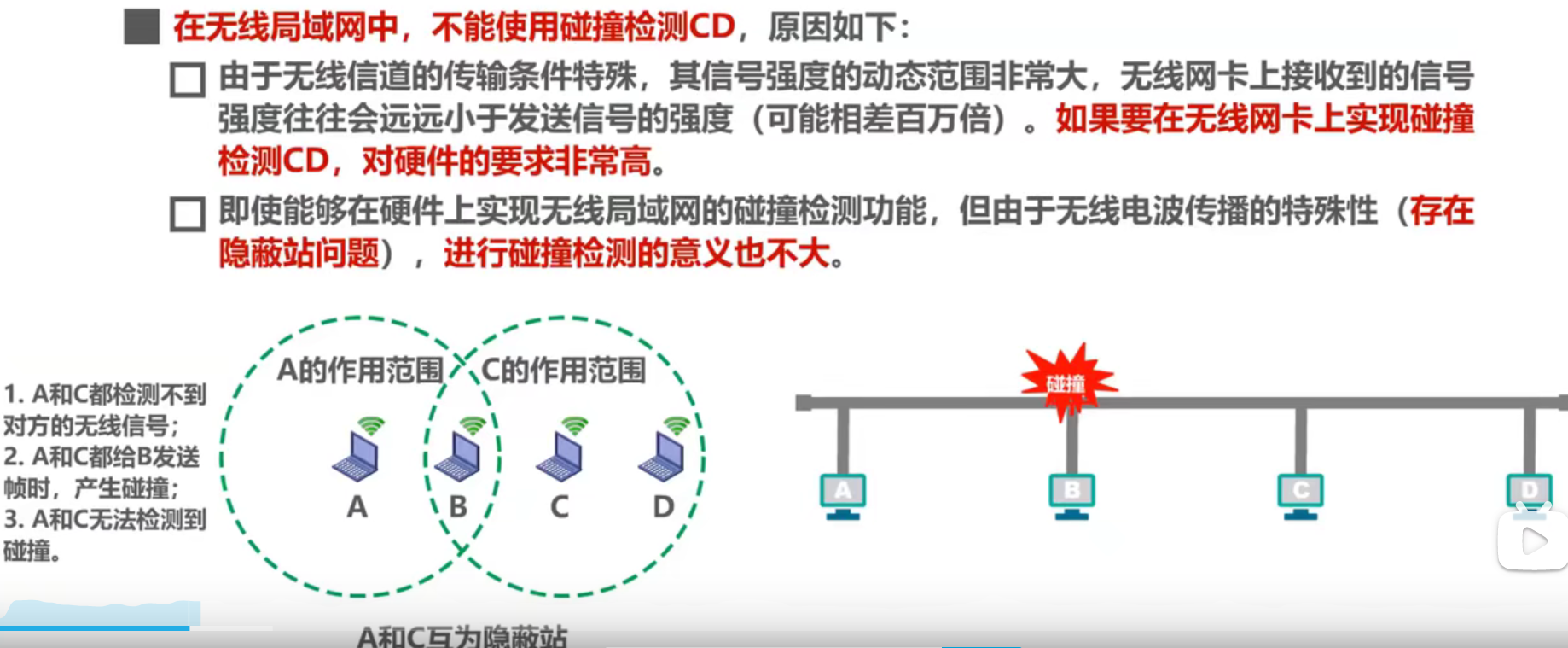
UDP 广播的过程
UDP Socket的使用过程
- 初始化网络库
- 创建SOCK_DGRAM类型的Socket。
- 绑定套接字。
- 发送、接收数据。
- 销毁套接字。
- 释放网络库。
广播数据包的原理
专门用于同时向网络中所有工作站进行发送的一个地址叫做广播地址。在使用TCP/IP 协议的网络中,主机标识段host ID 为全1 的IP 地址为广播地址。如果你的IP为:192.168.1.39,子网掩码为:255.255.255.0,则广播地址为:192.168.1.255;如果IP为192.168.1.39,子网掩码为:255.255.255.192,则广播地址为:192.168.1.63。
如果只想在本网络内广播数据,只要向广播地址发送数据包即可,这种数据包可以被路由,它会经由 路由器 到达本网段内的所有主机,此种广播也叫直接广播;如果想在整个网络中广播数据,要向255.255.255.255发送数据包,这种数据包不会被路由,它只能到达本物理网络中的所有主机,此种广播叫有限广播。
使用UDP协议发送、接收广播包的过程。
假如我们要向192.168.0.X,子网掩码为:255.255.255.0的子网中发送广播包。
DNS 的过程
https://zhuanlan.zhihu.com/p/55240680
需要记忆的 TCP 流程图
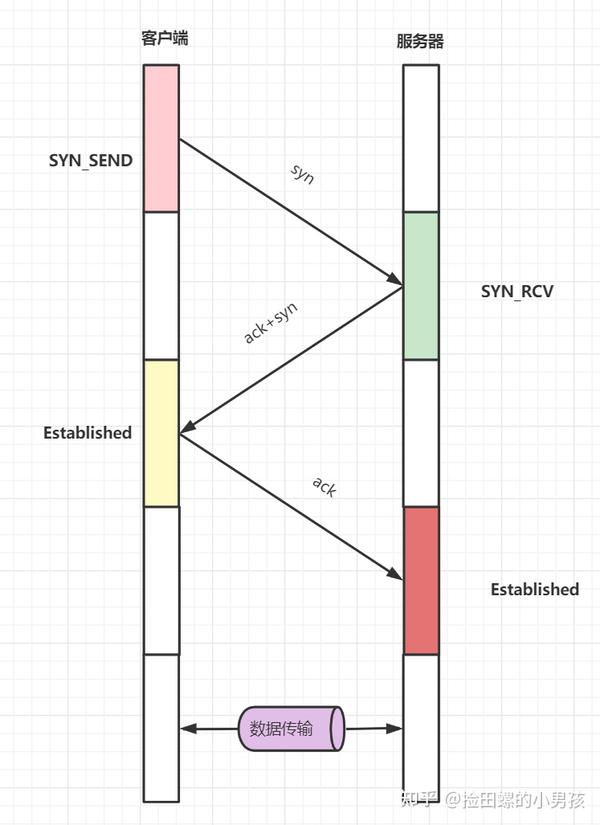
开始客户端和服务器都处于CLOSED状态,然后服务端开始监听某个端口,进入LISTEN状态
- 第一次握手(SYN=1, seq=x),发送完毕后,客户端进入 SYN_SEND 状态
- 第二次握手(SYN=1, ACK=1, seq=y, ACKnum=x+1), 发送完毕后,服务器端进入 SYN_RCVD 状态。
- 第三次握手(ACK=1,ACKnum=y+1),发送完毕后,客户端进入 ESTABLISHED 状态,当服务器端接收到这个包时,也进入 ESTABLISHED 状态,TCP 握手,即可以开始数据传输。
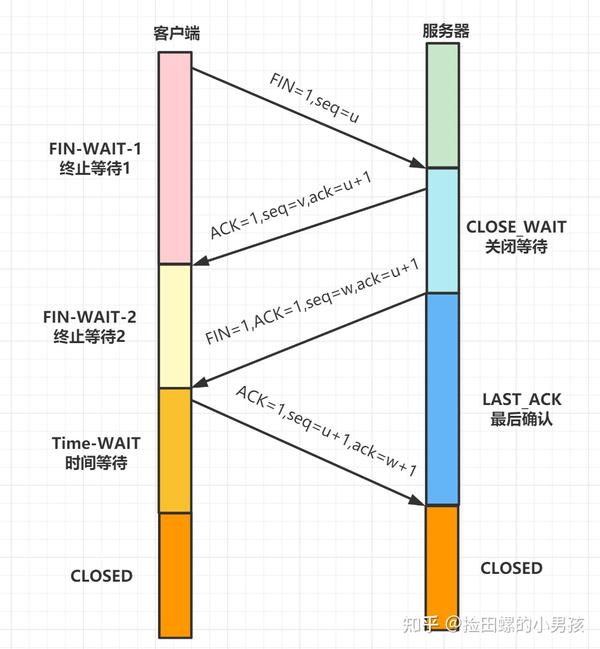
第一次挥手(FIN=1,seq=u),发送完毕后,客户端进入FIN_WAIT_1 状态
第二次挥手(ACK=1,ack=u+1,seq =v),发送完毕后,服务器端进入CLOSE_WAIT 状态,客户端接收到这个确认包之后,进入 FIN_WAIT_2 状态
第三次挥手(FIN=1,ACK1,seq=w,ack=u+1),发送完毕后,服务器端进入LAST_ACK 状态,等待来自客户端的最后一个ACK。
第四次挥手(ACK=1,seq=u+1,ack=w+1),客户端接收到来自服务器端的关闭请求,发送一个确认包,并进入 TIME_WAIT状态,等待了某个固定时间(两个最大段生命周期,2MSL,2 Maximum Segment Lifetime)之后,没有收到服务器端的 ACK ,认为服务器端已经正常关闭连接,于是自己也关闭连接,进入 CLOSED 状态。服务器端接收到这个确认包之后,关闭连接,进入 CLOSED 状态。
TCP 可靠传输原理
校验和
三者检验和的异同
TCP和UDP检验和是一个端到端的检验和,由发送端计算,然后由接收端验证。
TCP和UDP检验和覆盖首部和数据,而IP首部中的检验和只覆盖IP的首部,不覆盖IP数据报中的任何数据。
TCP的检验和是必需的,而UDP的检验和是可选的。
TCP和UDP计算检验和时,都要加上一个12字节的伪首部。
奇偶校验
在发送的数据后面添加1位奇偶校验位,使整个数据中1的个数位奇数(奇校验)或偶数(偶校验)。

-
原理: 最后一位 bit 放 1 或者 0 ,表示数据中有奇数个 1 ,偶数个0
-
然后接收方这边去数,是不是有偶数个1 【出现偶数个1 就出错】
-
例如还是ASCII码 大写字母 A
奇校验 正确码流 11000001
错1位 11000011 变成了偶数个1,能检测出错误
错2位 11000010 变成了奇数个1,检测不出错误
错3位 11001010 变成了偶数个1,能检测出错误
-
CRC 循环冗余校验原理
回退N步协议
发送方将0-4号分组,依次连续发送出去,经过互联网的传输,正确到达了接收方,在没有出现乱序和误码,接收方按序接收他们,每接收1个,接收方就向前滑动一个位置,并给发送方发送针对所接收分组的确认分组,0-4号确认分组经互联网的传输正确达到了发送方,发送方每接收一个接收,就向前滑动一个位置,随后,发送方将收到确认的数据分组从缓存中删除了,接收方将确认的数据交给上层。
「累积确认」
接收方不一定要对收到的数据分组逐个发送确认,而是收到几个数据分组后,对按序到达的最后一个数据分组发送确认,$ACK_n$表示序号为n及以前的所有数据分组都已正确接收。
「优点」
- 即使确认部分分组丢失,发送方也可不必重传!
- 减少接收方的开销。
「缺点」
- 不能向发送方及时反映出接收方已正确接收的数据分组信息。
「出差错情况」

在本例中尽管序号为1076的数据分组正确到达接收方,由于5号分组出现了误码不被接收,他们也会受到牵连不被接收,发送方还要重传这些数据分组,这就是回退n帧(Go-back-N)。
在本例中,当发送方窗口尺寸超过7时也会出现问题(接收方无法分辨新旧分组),在此不做解释!
HTTP 拆包问题的解决方法
- 消息定长
- 消息之间添加特定分隔符
- 显式长度,比如先发送4个字节表示消息的长度,紧接着发送消息
- 结合上面各种策略
http协议采用的策略
- 请求头以特定的符号("\r\n")结束,符合策略2,如果有请求体,则请求头中会有表示请求体的长度,符合策略3
常见 http状态码
- 301 表示 永久重定向
- 302 表示临时重定向
TCP 定时器有几种
1.建立连接定时器(connection-establishment timer) 2.重传定时器(retransmission timer) 3.延迟应答定时器(delayed ACK timer) 4.坚持定时器(persist timer) 5.保活定时器(keepalive timer) 6.FIN_WAIT_2定时器(FIN_WAIT_2 timer) 7.TIME_WAIT定时器 (TIME_WAIT timer, 也叫 2MSL timer)
http 1.2 2.0 3.0 版本都怎么优化的
http1.1
原理
-
HTTP用“whitespace-delimited”方式编码的。 用空格、回车来编码,是因为HTTP在诞生之初追求可读性,这样更有利于它的推广。
-
一个资源的请求响应返回后,下一个请求才能发送。这被称为线头阻塞。
http/2
HTTP/2的多路复用和头部压缩特性。
- (不同的请求共用一个TCP连接)允许资源并行下载,而不是一个个的下载, 避免线头阻塞的问题
- 头部压缩 (减少了多个HTTP请求的开销)
头部压缩是什么:
当服务器收到客户端的请求时,它会检查请求头中的 “Accept-Encoding” 头,如果发现 “gzip” 或 “deflate” 作为压缩方法,那么服务器将使用相应的压缩算法对请求头进行压缩
压缩后的请求头被发送给客户端。客户端解压压缩后的请求头,并继续处理请求 ,客户端可以选择是否对响应头进行压缩。如果客户端和服务器都支持头部压缩,那么客户端会尝试压缩响应头。 由于请求和响应头的压缩,HTTP/2 减少了数据的大小,提高了传输效率。 减小对网络请求带宽的消耗
文章作者 LYR
上次更新 2021-08-17