rabbitMQ 、Kafka、ActiveMq 等

文章目录
几款 MQ 的性能对比
ActiveMQ: JMS 规范 (java 定义的规范),支持事务,支持XA 协议(支持事务消息), 没有生成大规模支撑场景,官方文档维护越来越少
RabbitMQ : erlang 语言开发,性能好、高并发、 支持多种语言 , 社区、文档方面有优势,erlang 语言不利于 java 程序员的二次开发,依赖社区开源的维护和升级,需要学习 AMQP 协议,学习成本相对较高。
以上吞吐量都在万级
kafka: 高性能,高可用, 生产环境有大规模使用场景,宕机容量有限 (超过 64个分区响应长度明显变长) 、社区更新慢
吞吐量 百万级别
rocketMq : java 实现, 方便二次开发,设计参考kafka, 高可用,高可靠(消息0丢失),社区活跃一般,支持语言较少, 吞吐量 单机十万级别。
kafka push 和 pull 优点和缺点
Push vs. Pull
作为一个messaging system,Kafka遵循了传统的方式,选择由producer向broker push消息并由consumer从broker pull消息。一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,采用非常不同的push模式。事实上,push模式和pull模式各有优劣。
push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
kafka 高性能高吞吐的原因
-
磁盘顺序读写 如果你是追加文件末尾按照顺序的方式来写数据的话,那么这种磁盘顺序写的性能基本上可以跟写内存的性能本身也是差不多的。
-
利用Page Cache空中接力的方式来实现高效读写,操作系统本身有一层缓存,叫做page cache,是在内存里的缓存,我们也可以称之为os cache,意思就是操作系统自己管理的缓存。原理就是Page Cache可以把磁盘中的数据缓存到内存中,把对磁盘的访问改为对内存的访问。

-
零拷贝方式
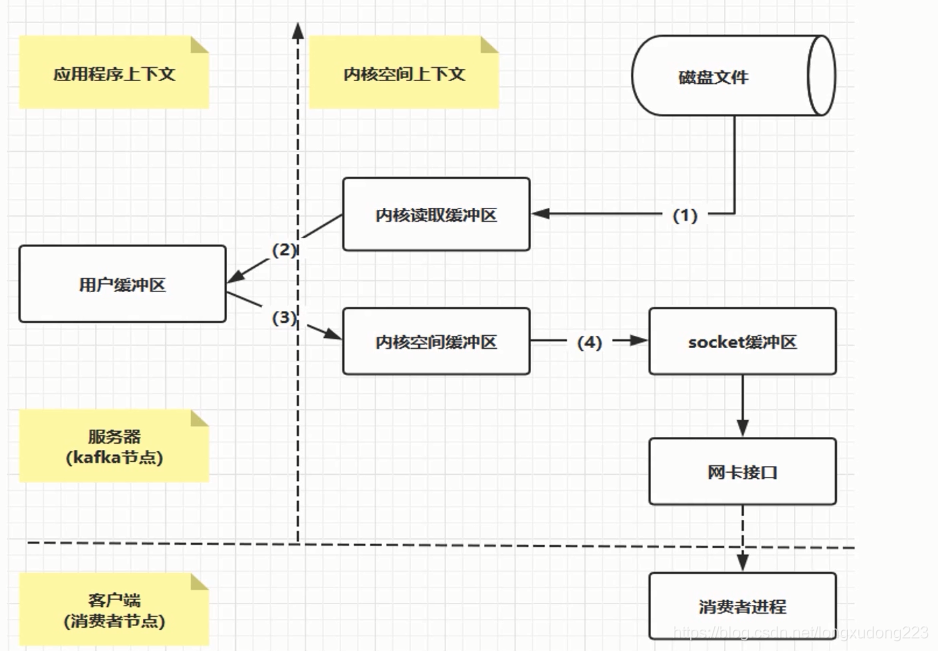
假如不用零拷贝方式,kafka从磁盘读数据发送给下游的消费者大概的过程为:kafka首先看看要读的数据在不在os cache里,如果不在的话就从磁盘文件里读取数据后放入os cache,接着再到应用程序进程的缓存里,再到操作系统层面的Socket缓存里,最后从Socket缓存里提取数据后发送到网卡,最后发送出去给消费者。
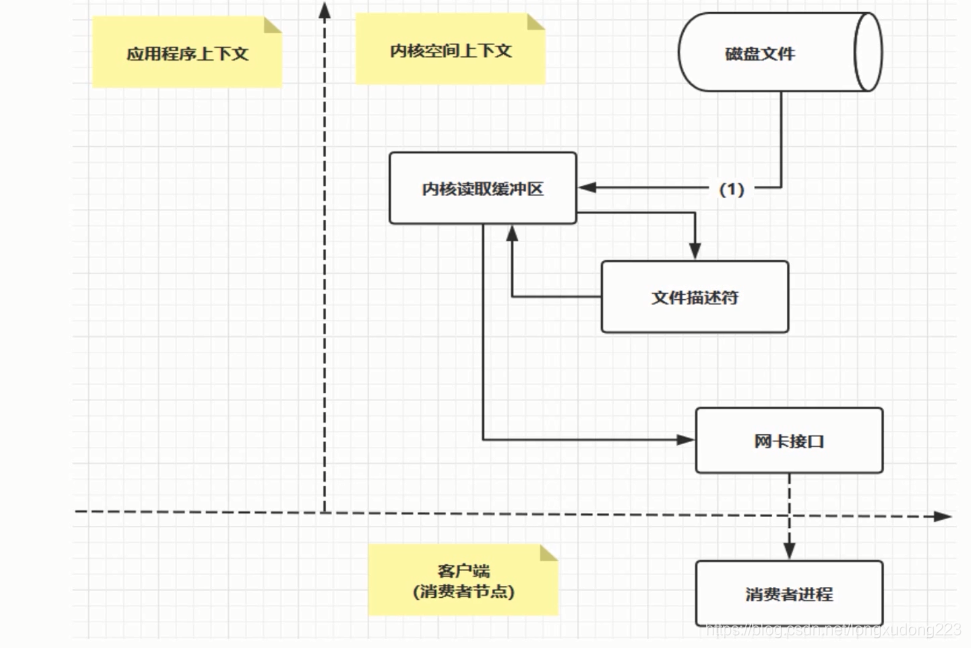
零拷贝:直接让操作系统的cache中的数据发送到网卡后传输给下游的消费者,直接跳过了两次拷贝数据的步骤,Socket缓存中仅仅会拷贝一个描述符过去,不会拷贝数据到Socket缓存 【相当于拷贝一个 指针引用过去,而不是值拷贝】。
文章作者 LYR
上次更新 2021-08-17