redis rdb 和 aof机制

文章目录
redis rdb 和 aof 机制
rdb: redis database
在指定时间内将内存中的数据集快照写入磁盘,实际操作过程就是一个 fork 一个子进程,先将数据写入临时文件,写入成功 后再替换之前的文件,用二进制压缩存储。
为什么Redis进行RDB持久化数据时,新起一个进程而不是在原进程中起一个线程来持久化数据
答案:主要是出于Redis性能的考虑,(1)Redis RDB持久化机制会阻塞主进程,这样主进程就无法响应客户端请求。(2)我们知道Redis对客户端响应请求的工作模型是单进程和单线程的,如果在主进程内启动一个线程,这样会造成对数据的竞争条件,为了避免使用锁降低性能。基于以上两点这就是为什么Redis通过启动一个进程来执行RDB了。
优点:
- 整个redis 数据库只包含一个文件 dump.rdb, 方便持久化
- 容灾性 好,方便备份
- 性能最大化,子进程执行 写操作,主进程继续处理,所以 IO最大化,单独使用子进程处理持久化,主进程无IO操作,保证redis 高性能
- 数据量比较大 比 AOF 启动效率要更高
AOF 原理
缺点:
1. AOF 文件比 RDB文件大,恢复速度慢
2. 数据集大的时候 ,比 rdb启动效率低
3. 运行效率没RDB 高
优点:
- 以文本的方式写入命令,可以打开文件看详细的操作记录
- 比较实时,
- 策略:
- 每秒同步
- 每修改同步
- 不同步
==子进程只执行保存操作(只保存 开始 到 子进程触发保存时间点的数据),不接受客户端的请求。即:在子进程执行持久化保存数据的时候,来自客户端的新数据子进程不会保存==
redis 为什么单线程这么快
redis 持久化可以 fork一个多进程来处理 【不一定严格说是单线程】
- redis 纯内存操作
- 单线程处理,没有线程上下文切换的代价
- redis 实现了一个队列, 通过一个事件循环, epoll 监听多个 文件描述符,注册个 回调进去,如果 有IO 事件了,就出发回调 执行。 【reactor模式】
- redis 网络事件处理器 是 一个单线程的, file event handler

多个 socket 并发产生不同的事件,多路复用程序要监听多个 socket,会先将 socket 放入一个队列,每次从队列有序,同步取出一个 socket 给事件分派器,事件分派器把 socket 给对应的事件处理器。 然后 socket 处理完成后, IO 多路复用 程序才将队列中的下一个 socket 给事件分派器。 文件时间分派器 会根据每个 socket 当前的事件, 来选择对应的事件处理器来处理。
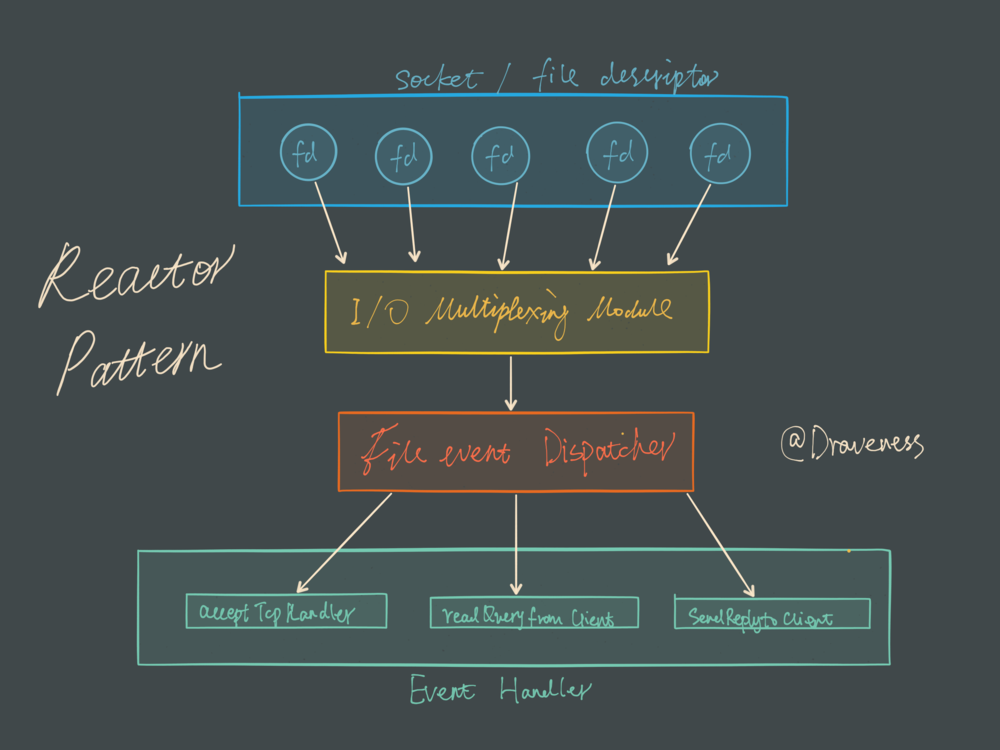


多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。对于文件来讲,就是监听一堆文件,某个文件写满则返回。对于redis来讲,就是用了上述技术去监听多个连接,当连接完成写入的时候,会监听到并返回:)
redis 过期键删除策略
- 惰性删除
- get 的时候再删除
- 定期删除
- 过段时间删除
redis 同时使用2种策略
redis 分布式锁 如何实现
- redis 高可用
- setnx + lua脚本 , 如果key 存在就获取不到锁
- 利用lua脚本 保证多个 redis 操作的原子性
- 考虑锁过期,需要用一个看门狗机制,定时任务定时去监听是否需要续约
- 同时还要考虑 redis 节点挂掉之后 是否需要采用红锁的方式, 向 N/2 + 1 个节点申请锁, 都申请到了才证明锁获取从, 这样就算某个redis 节点挂掉,锁也不能被其他客户端获取。
分布式锁,当我们请求一个分布式锁的时候,成功了,但是这时候slave还没有复制我们的锁,masterDown了,我们的应用继续请求锁的时候,会从继任了master的原slave上申请,也会成功。
这就会导致,同一个锁被获取了不止一次。
- 只有在大多数节点上获取到了锁,而且总的获取时间小于锁的超时时间的情况下,认为锁获取成功了。
文章作者 LYR
上次更新 2021-08-17