协程的原理
 次阅读
次阅读
文章目录
1:1 线程模型
以上我提到的内核线程(Kernel-Level Thread, KLT)是由操作系统内核支持的线程,内核通过调度器对线程进行调度,并负责完成线程的切换。
我们知道在 Linux 操作系统编程中,往往都是通过 fork() 函数创建一个子进程来代表一个内核中的线程。一个进程调用 fork() 函数后,系统会先给新的进程分配资源,例如,存储数据和代码的空间。然后把原来进程的所有值都复制到新的进程中,只有少数值与原来进程的值(比如 PID)不同,这相当于复制了一个主进程。
采用 fork() 创建子进程的方式来实现并行运行,会产生大量冗余数据,即占用大量内存空间,又消耗大量 CPU 时间用来初始化内存空间以及复制数据。
如果是一份一样的数据,为什么不共享主进程的这一份数据呢?这时候轻量级进程(Light Weight Process,即 LWP)出现了。
相对于 fork() 系统调用创建的线程来说,LWP 使用 clone() 系统调用创建线程,该函数是将部分父进程的资源的数据结构进行复制,复制内容可选,且没有被复制的资源可以通过指针共享给子进程。因此,轻量级进程的运行单元更小,运行速度更快。LWP 是跟内核线程一对一映射的,每个 LWP 都是由一个内核线程支持。
N:1 线程模型
1:1 线程模型由于跟内核是一对一映射,所以在线程创建、切换上都存在用户态和内核态的切换,性能开销比较大。除此之外,它还存在局限性,主要就是指系统的资源有限,不能支持创建大量的 LWP。
N:1 线程模型就可以很好地解决 1:1 线程模型的这两个问题。
该线程模型是在用户空间完成了线程的创建、同步、销毁和调度,已经不需要内核的帮助了,也就是说在线程创建、同步、销毁的过程中不会产生用户态和内核态的空间切换,因此线程的操作非常快速且低消耗。
N:M 线程模型
N:1 线程模型的缺点在于操作系统不能感知用户态的线程,因此容易造成某一个线程进行系统调用内核线程时被阻塞,从而导致整个进程被阻塞。
N:M 线程模型是基于上述两种线程模型实现的一种混合线程管理模型,即支持用户态线程通过 LWP 与内核线程连接,用户态的线程数量和内核态的 LWP 数量是 N:M 的映射关系。
目前 Java 在 Linux 操作系统下采用的是用户线程加轻量级线程,一个用户线程映射到一个内核线程,即 1:1 线程模型。由于线程是通过内核调度,从一个线程切换到另一个线程就涉及到了上下文切换。
而 Go 语言是使用了 N:M 线程模型实现了自己的调度器,它在 N 个内核线程上多路复用(或调度)M 个协程,协程的上下文切换是在用户态由协程调度器完成的,因此不需要陷入内核,相比之下,这个代价就很小了。
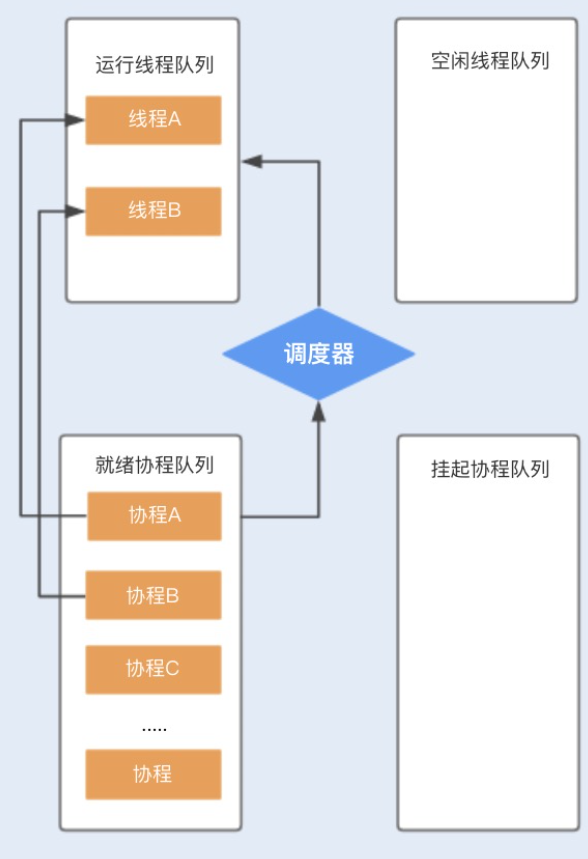
协程少了由于同步资源竞争带来的 CPU 上下文切换,I/O 密集型的应用比较适合使用,特别是在网络请求中,有较多的时间在等待后端响应,协程可以保证线程不会阻塞在等待网络响应中,充分利用了多核多线程的能力。而对于 CPU 密集型的应用,由于在多数情况下 CPU 都比较繁忙,协程的优势就不是特别明显了。
协程与线程最大的不同就是,线程是通过共享内存来实现数据共享,而协程是使用了通信的方式来实现了数据共享,主要就是为了避免内存共享数据而带来的线程安全问题。
协程又是一种轻量级资源,即使创建了上千个协程,对于系统来说也不是很大的负担,但如果在程序中创建上千个线程,那系统可真就压力山大了。可以说,协程的设计方式极大地提高了线程的使用率。
在 Java 中的协程目前还不是很稳定,重点是缺乏大型项目的验证,可以说 Java 的协程设计还有很长的路要走。
文章作者 LYR
上次更新 2021-08-17