java_多线程_锁优化
 次阅读
次阅读
文章目录
**在并发编程中,多个线程访问同一个共享资源时,我们必须考虑如何维护数据的原子性。**在 JDK1.5 之前,Java 是依靠 Synchronized 关键字实现锁功能来做到这点的。Synchronized 是 JVM 实现的一种内置锁,锁的获取和释放是由 JVM 隐式实现。
到了 JDK1.5 版本,并发包中新增了 Lock 接口来实现锁功能,它提供了与 Synchronized 关键字类似的同步功能,只是在使用时需要显示获取和释放锁。
Lock 同步锁是基于 Java 实现的,而 Synchronized 是基于底层操作系统的 Mutex Lock 实现的,每次获取和释放锁操作都会带来用户态和内核态的切换,从而增加系统性能开销。因此,在锁竞争激烈的情况下,Synchronized 同步锁在性能上就表现得非常糟糕,它也常被大家称为重量级锁。
特别是在单个线程重复申请锁的情况下,JDK1.5 版本的 Synchronized 锁性能要比 Lock 的性能差很多。例如,在 Dubbo 基于 Netty 实现的通信中,消费端向服务端通信之后,由于接收返回消息是异步,所以需要一个线程轮询监听返回信息。而在接收消息时,就需要用到锁来确保 request session 的原子性。如果我们这里使用 Synchronized 同步锁,那么每当同一个线程请求锁资源时,都会发生一次用户态和内核态的切换。
到了 JDK1.6 版本之后,Java 对 Synchronized 同步锁做了充分的优化,甚至在某些场景下,它的性能已经超越了 Lock 同步锁。这一讲我们就来看看 Synchronized 同步锁究竟是通过了哪些优化,实现了性能地提升。
|
|
JVM 中的同步是基于进入和退出管程(Monitor)对象实现的。每个对象实例都会有一个 Monitor,Monitor 可以和对象一起创建、销毁。Monitor 是由 ObjectMonitor 实现,而 ObjectMonitor 是由 C++ 的 ObjectMonitor.hpp 文件实现,如下所示:
偏向锁的作用就是,当一个线程再次访问这个同步代码或方法时,该线程只需去对象头的 Mark Word 中去判断一下是否有偏向锁指向它的 ID,无需再进入 Monitor 去竞争对象了。当对象被当做同步锁并有一个线程抢到了锁时,锁标志位还是 01,“是否偏向锁”标志位设置为 1,并且记录抢到锁的线程 ID,表示进入偏向锁状态。
一旦出现其它线程竞争锁资源时,偏向锁就会被撤销。偏向锁的撤销需要等待全局安全点,暂停持有该锁的线程,同时检查该线程是否还在执行该方法,如果是,则升级锁,反之则被其它线程抢占。
因此,在高并发场景下,当大量线程同时竞争同一个锁资源时,偏向锁就会被撤销,发生 stop the word 后, 开启偏向锁无疑会带来更大的性能开销,这时我们可以通过添加 JVM 参数关闭偏向锁来调优系统性能,示例代码如下:
|
|
当有另外一个线程竞争获取这个锁时,由于该锁已经是偏向锁,当发现对象头 Mark Word 中的线程 ID 不是自己的线程 ID,就会进行 CAS 操作获取锁,如果获取成功,直接替换 Mark Word 中的线程 ID 为自己的 ID,该锁会保持偏向锁状态;如果获取锁失败,代表当前锁有一定的竞争,偏向锁将升级为轻量级锁。
轻量级锁适用于线程交替执行同步块的场景,绝大部分的锁在整个同步周期内都不存在长时间的竞争。
动态编译实现锁消除 / 锁粗化
除了锁升级优化,Java 还使用了编译器对锁进行优化。JIT 编译器在动态编译同步块的时候,借助了一种被称为逃逸分析的技术,来判断同步块使用的锁对象是否只能够被一个线程访问,而没有被发布到其它线程。
确认是的话,那么 JIT 编译器在编译这个同步块的时候不会生成 synchronized 所表示的锁的申请与释放的机器码,即消除了锁的使用。在 Java7 之后的版本就不需要手动配置了,该操作可以自动实现。
锁粗化同理,就是在 JIT 编译器动态编译时,如果发现几个相邻的同步块使用的是同一个锁实例,那么 JIT 编译器将会把这几个同步块合并为一个大的同步块,从而避免一个线程“反复申请、释放同一个锁“所带来的性能开销。
减小锁粒度
除了锁内部优化和编译器优化之外,我们还可以通过代码层来实现锁优化,减小锁粒度就是一种惯用的方法。
当我们的锁对象是一个数组或队列时,集中竞争一个对象的话会非常激烈,锁也会升级为重量级锁。我们可以考虑将一个数组和队列对象拆成多个小对象,来降低锁竞争,提升并行度。
最经典的减小锁粒度的案例就是 JDK1.8 之前实现的 ConcurrentHashMap 版本。我们知道,HashTable 是基于一个数组 + 链表实现的,所以在并发读写操作集合时,存在激烈的锁资源竞争,也因此性能会存在瓶颈。而 ConcurrentHashMap 就很很巧妙地使用了分段锁 Segment 来降低锁资源竞争,如下图所示:
lock 实现原理
Lock 锁是基于 Java 实现的锁,Lock 是一个接口类,常用的实现类有 ReentrantLock、ReentrantReadWriteLock(RRW),它们都是依赖 AbstractQueuedSynchronizer(AQS)类实现的。
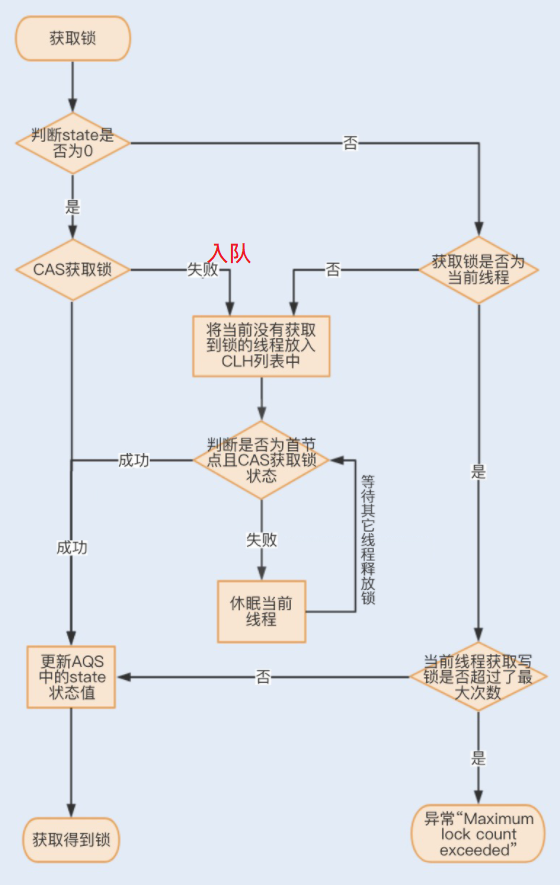
AQS 类结构中包含一个基于链表实现的等待队列(CLH 队列),用于存储所有阻塞的线程,AQS 中还有一个 state 变量,该变量对 ReentrantLock 来说表示加锁状态。
锁分离优化 Lock 同步锁
在大部分业务场景中,读业务操作要远远大于写业务操作。而在多线程编程中,读操作并不会修改共享资源的数据,如果多个线程仅仅是读取共享资源,那么这种情况下其实没有必要对资源进行加锁。如果使用互斥锁,反倒会影响业务的并发性能,那么在这种场景下,有没有什么办法可以优化下锁的实现方式呢?
**一个线程尝试获取写锁时,**会先判断同步状态 state 是否为 0。如果 state 等于 0,说明暂时没有其它线程获取锁;如果 state 不等于 0,则说明有其它线程获取了锁。
此时再判断同步状态 state 的低 16 位(w)是否为 0,如果 w 为 0,则说明其它线程获取了读锁,此时进入 CLH 队列进行阻塞等待;如果 w 不为 0,则说明其它线程获取了写锁,此时要判断获取了写锁的是不是当前线程,若不是就进入 CLH 队列进行阻塞等待;若是,就应该判断当前线程获取写锁是否超过了最大次数,若超过,抛异常,反之更新同步状态。
文章作者 LYR
上次更新 2021-08-17