
etcd和Raft算法

文章目录
raft算法分析
raft是什么? 算法还是协议?
两种说法都对,协议强调的是实现节点间通信过程, 算法一般在理论
一致性还是共识? 什么是一致性
论文中多数用的是 consensus, consistent 指的是 log consistent 日志副本一致性, 应该说: raft共识算法取得日志副本一致性 共识算法 是系统实现层面的描述, 一致性是应用业务层面的描述, 或者说是一种容错系统 fault tolerance
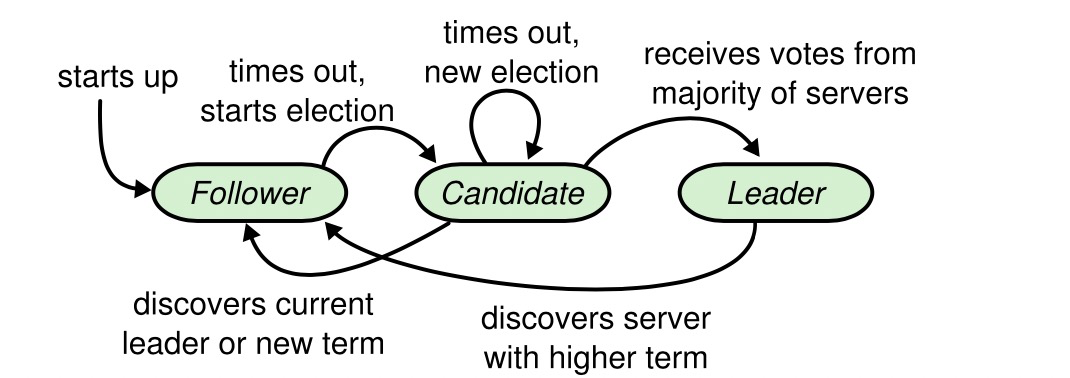
raft算节类型
角色 leader主 candidate候选人 follower从,起始状态都是follower
这里举一个例子来解释这个问题。 假设三个节点 A B C 存储用户资金账户 阶段一 初始状态所有账户资金为零,我们允许A B C 同时都能处理用户请求,小菜(客户端)请求A 节点 存入 100,为了让B也能正常处理,那么需要A将交易记录(日志)复制给 B C 节点,小菜又请求B 节点要从账户取100 如果A总是能将日志成功复制到B、C,并且取操作总是在存入之后,处理是正确的
以上场景即使 B节点收到的日志时序是,t4 t2 ,如果能保障t2<t4 等全部事件收到之后,排序一下日志操作,复制失败无限重试,如果能保证全局日志时序,能够取得最终一致,但是做不到强一致。 但是鉴于网络的不可靠和所有机器的时钟(即使使用原子钟)不可能完全一样,不可能取得全局时序。换句话说发生在A的日志时间t1和发生在B的日志时间t4 无法正确判断大小关系
几个定时器及超时时间 election time out 选举定时器时间,follower超过n未收到主的心跳,将自己切换为候选人开始选举(造反啦) 心跳定时器 heartbeat 主节点定期给follower发送心跳消息(老子还或者说给我老实点) 选举定时器,candidate 开始选举超过时间未成功选出leader,重新开启选举。
活锁解决
选举超时时间 150-300ms 避免来活锁
降低平分选票概率,但是仍然不可能 例子:A B C 几乎同时成为候选人,各自投自己一票,没人有拿到2票
Raft 使用心跳(heartbeat)触发Leader选举。当服务器启动时,初始化为Follower。Leader向所有Followers周期性发送heartbeat。如果Follower在选举超时时间内没有收到Leader的heartbeat,就会等待一段随机的时间后发起一次Leader选举。
Follower将其当前term加一然后转换为Candidate。它首先给自己投票并且给集群中的其他服务器发送 RequestVote RPC (RPC细节参见八、Raft算法总结)。结果有以下三种情况:
赢得了多数的选票,成功选举为Leader; 收到了Leader的消息,表示有其它服务器已经抢先当选了Leader; 没有服务器赢得多数的选票,Leader选举失败,等待选举时间超时后发起下一次选举
选举出Leader后,Leader通过定期向所有Followers发送心跳信息维持其统治。若Follower一段时间未收到Leader的心跳则认为Leader可能已经挂了,再次发起Leader选举过程。
Raft保证选举出的Leader上一定具有最新的已提交的日志,这一点将在四、安全性中说明。
ETCD 学习
提供配置共享和服务发现的系统比较多,其中最为大家熟知的是 Zookeeper,而 etcd 可以算得上是后起之秀了。在项目实现、一致性协议易理解性、运维、安全等多个维度上,etcd 相比 zookeeper 都占据优势。
本文选取 Zookeeper 作为典型代表与 etcd 进行比较,而不考虑 Consul 项目作为比较对象,原因为 Consul 的可靠性和稳定性还需要时间来验证(项目发起方自身服务并未使用Consul,自己都不用)。
一致性协议: etcd 使用 Raft 协议,Zookeeper 使用 ZAB(类PAXOS协议),前者容易理解,方便工程实现; 运维方面:etcd 方便运维,Zookeeper 难以运维; 数据存储:etcd 多版本并发控制(MVCC)数据模型 , 支持查询先前版本的键值对 项目活跃度:etcd 社区与开发活跃,Zookeeper 感觉已经快死了; API:etcd 提供 HTTP+JSON, gRPC 接口,跨平台跨语言,Zookeeper 需要使用其客户端; 访问安全方面:etcd 支持 HTTPS 访问,Zookeeper 在这方面缺失;
etcd 比较多的应用场景是用于服务发现,服务发现 (Service Discovery) 要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。和 Zookeeper 类似,etcd 有很多使用场景,包括:
分布式定时任务
在开发过程中,往往需要系统执行一些定时的任务,例如我们需要将数据进行迁移,又或者需要做一些数据的离线统计工作,这些都需要定时任务来进行处理。传统的方法就是quartz来写个定时任务,然后该机器就会在特定时间执行我们要执行的代码,但是假如这台机器出现故障,那么这个定时任务就不会执行。 在集群环境中,我们希望即使在某台机器出现故障,那么其他机器就可以将任务接管过来,继续执行任务。
|
|
etcd 其他介绍
etcd 目前支持 V2 和 V3 两个大版本,这两个版本在实现上有比较大的不同,一方面是对外提供接口的方式,另一方面就是底层的存储引擎,V2 版本的实例是一个纯内存的实现,所有的数据都没有存储在磁盘上,而 V3 版本的实例就支持了数据的持久化。
参考教程
golang 操作 etcd实战
编译报错解决
|
|
简单KV操作实战
|
|
|
|
文章作者 lyr
上次更新 2022-05-11