
docker理论基础

文章目录
docker

docker理论基础
基于 Linux 内核的 Cgroup,Namespace,以及 Union FS 等技术,对进程进行封装隔离,属于操作系统 层面的虚拟化技术,由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。 • 最初实现是基于 LXC,从 0.7 以后开始去除 LXC,转而使用自行开发的 Libcontainer,从 1.11 开始,则 进一步演进为使用 runC 和 Containerd。 • Docker 在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容 器的创建和维护,使得 Docker 技术比虚拟机技术更为轻便、快捷。
容器操作
启动: • docker run
- -it 交互
- -d 后台运行
- -p 端口映射
- -v 磁盘挂载
• 启动已终止容器 docker start • 停止容器 docker stop • 查看容器进程 docker ps
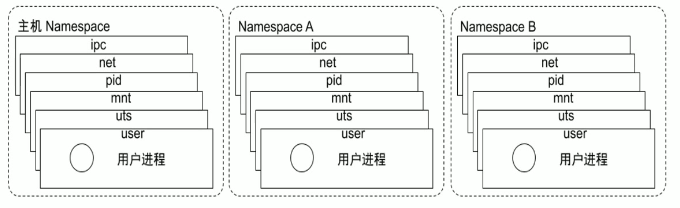
Namespace
• Linux Namespace 是一种 Linux Kernel 提供的资源隔离方案: • 系统可以为进程分配不同的 Namespace; • 并保证不同的 Namespace 资源独立分配、进程彼此隔离,即不同的 Namespace 下的进程互不干扰
- Namespace 可以隔离进程Id、主机名、用户ID、文件名、网络访问和进程间通信等相关资源
- 参考油管教程
[[post/14.新语言学习记录/语言技术/Golang/容器技术/cgroup原理 | cgroup原理]] [[post/14.新语言学习记录/云原生原理/Docker学习/linux control groups(cgroups) | group应用]]
Cgroup
Cgroups (Control Groups)是 Linux 下用于对一个或一组进程进行资源控制和监控的机制; • 可以对诸如 CPU 使用时间、内存、磁盘 I/O 等进程所需的资源进行限制; • 不同资源的具体管理工作由相应的 Cgroup 子系统(Subsystem)来实现 ; • 针对不同类型的资源限制,只要将限制策略在不同的的子系统上进行关联即可 ; • Cgroups 在不同的系统资源管理子系统中以层级树(Hierarchy)的方式来组织管理:每个 Cgroup 都可以 包含其他的子 Cgroup,因此子 Cgroup 能使用的资源除了受本 Cgroup 配置的资源参数限制,还受到父 Cgroup 设置的资源限制 。
隔离原理 -Linux namespace
不同的进程 会有一个 PID ,不同的进程 pid 可以相同,也可以不同, 我们可以把 一组需要 手动管理的进程 放在 一个 PID namespace 里面, 也就是说 每个 namespace 的 pid 是不一样的,就能做到互相隔离
这是 linux 内核支持的
隔离原理2. - net namespace
- 网络隔离是通过 net namespace 实现的, 每个 net namespace 有独立的 network devices, IP
addresses, IP routing tables,
/proc/net目录。 - Docker 默认采用 veth 的方式将 container 中的虚拟网卡同 host 上的一个
docker bridge: docker0连接 在一起
隔离原理3. -ipc namespace
- Container 中进程交互还是采用 linux 常见的进程间交互方法 (interprocess communication – IPC), 包 括常见的信号量、消息队列和共享内存。
- container 的进程间交互实际上还是 host上 具有相同 Pid namespace 中的进程间交互,因此需要在 IPC 资源申请时加入 namespace 信息 - 每个 IPC 资源有一个唯一的 32 位 ID。
bash 操作 namespace
|
|
cgroups 资源管控
- cgroups (control groups) 是 linux 下用于对一个或者一组进程进行资源控制和监控的机制
- 可以对诸如 CPU 使用时间、内存、磁盘I/O等进程所需的资源进行限制
- 不同资源对具体隔离工作由相应的 Cgroup 子系统 (subsystem) 来实现
- 针对不同类型的资源限制,只要将限制策略在不同的子系统上进行关联即可
- Cgroups 在不同的系统资源管理子系统中以层级树的方式来组织和管理: 每个 cgroup 都可以包含其他的子Cgroup,因此 Cgroup 能使用的资源除了受本Cgroup 配置的资源参数限制,还受到父Cgroup 设置的资源限制
CPU 子系统
cpu.shares: 可出让的能获得 CPU 使用时间的相对值。 cpu.cfs_period_us:cfs_period_us 用来配置时间周期长度,单位为 us(微秒)。 cpu.cfs_quota_us:cfs_quota_us 用来配置当前 Cgroup 在 cfs_period_us 时间内最多能使用的 CPU 时间数,单 位为 us(微秒)。 cpu.stat : Cgroup 内的进程使用的 CPU 时间统计。 nr_periods : 经过 cpu.cfs_period_us 的时间周期数量。 nr_throttled : 在经过的周期内,有多少次因为进程在指定的时间周期内用光了配额时间而受到限制。 throttled_time : Cgroup 中的进程被限制使用 CPU 的总用时,单位是 ns(纳秒)。

|
|
linux进程调度器
内核默认提供了5个调度器,Linux 内核使用 struct sched_class 来对调度器进行抽象: • Stop 调度器,stop_sched_class:优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占; • Deadline 调度器,dl_sched_class:使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进 行调度运行; • RT 调度器, rt_sched_class:实时调度器,为每个优先级维护一个队列; • CFS 调度器, cfs_sched_class:完全公平调度器,采用完全公平调度算法,引入虚拟运行时间概念; • IDLE-Task 调度器, idle_sched_class:空闲调度器,每个 CPU 都会有一个 idle 线程,当没有其他进程 可以调度时,调度运行 idle 线程。
CFS 调度器 • CFS 是 Completely Fair Scheduler 简称,即完全公平调度器。 • CFS 实现的主要思想是维护为任务提供处理器时间方面的平衡,这意味着应给进程分配相当数量的处理器。 • 分给某个任务的时间失去平衡时,应给失去平衡的任务分配时间,让其执行。 • CFS 通过虚拟运行时间(vruntime)来实现平衡,维护提供给某个任务的时间量。 • vruntime = 实际运行时间*1024 / 进程权重 • 进程按照各自不同的速率在物理时钟节拍内前进,优先级高则权重大,其虚拟时钟比真实时钟跑得慢,但 获得比较多的运行时间。
ve runtime 红黑树 CFS 调度器没有将进程维护在运行队列中,而是维护了一个以虚拟运行时间为顺序的红黑树。 红黑树的主要 特点有:
- 自平衡,树上没有一条路径会比其他路径长出俩倍。
- O(log n) 时间复杂度,能够在树上进行快速高效地插入或删除进程。
podman
docker 后台有一个 dockerd的 进程, docker的各种命令 就是 和 dockerd 进程交互使用的。
docker 概念梳理
docker 是基于 linux 来实现的,如果要在windows下使用,就要通过 hyperv 上面装一个 linux虚拟机来实现,mac下 就要 装linux 虚拟机实现。
- 打开docker调试模式,查看详细日志,根据调试日志去查找对应的Docker代码,发现 dockerd请求 containerd无响应。
- 发送linux siguser1信号量,打印 Golang堆栈信息
- 结合 内核 Cgroups相关日志,定位和解决问题
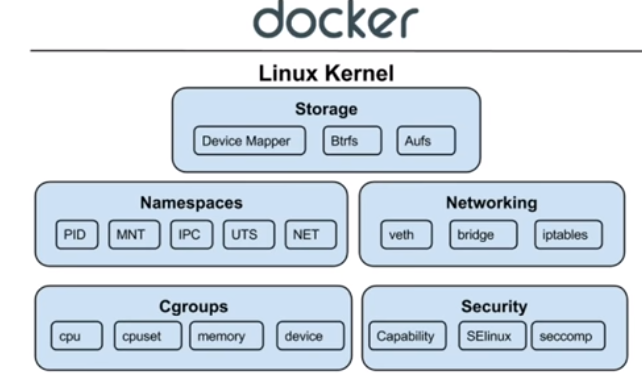
docker实现的三大机制
-
namespace 【隔离 进程,内核隔离】
- pid namespace 隔离进程 id
- net namespace 隔离网络接口
- mnt namespace 文件系统挂载点隔离
- ipc namespace 信号量,消息队列和共享内存的隔离
- uts namespace 主机名和域名隔离
-
cgroup 【限制资源调用】,限制和隔离进程的资源使用情况【CPU、内存、磁盘、网络等】
-
联合文件系统 【镜像构建】【实现容器的写时复制,定向分层构建和存储】
- 又叫 UnionFs,是一种通过创建文件层进程操作的文件系统,常用联合文件系统有 AUFS、 Overlay 和 Devicemapper 等
安装Docker ,需要centos7及以上版本,建议使用overlay2存储驱动程序
chroot实现简单的 docker进程
|
|

在经过 chroot 之后,系统读取到的目录和文件将不在是旧系统根下的而是新根下(即被指定的新的位置)的目录结构和文件,因此它带来的好处大致有以下3个:
-
增加了系统的安全性,限制了用户的权力;
在经过 chroot 之后,在新根下将访问不到旧系统的根目录结构和文件,这样就增强了系统的安全性。这个一般是在登录 (login) 前使用 chroot,以此达到用户不能访问一些特定的文件。
-
建立一个与原系统隔离的系统目录结构,方便用户的开发;
使用 chroot 后,系统读取的是新根下的目录和文件,这是一个与原系统根下文件不相关的目录结构。在这个新的环境中,可以用来测试软件的静态编译以及一些与系统不相关的独立开发。
-
切换系统的根目录位置,引导 Linux 系统启动以及急救系统等。
chroot 的作用就是切换系统的根位置,而这个作用最为明显的是在系统初始引导磁盘的处理过程中使用,从初始 RAM 磁盘 (initrd) 切换系统的根位置并执行真正的 init。另外,当系统出现一些问题时,我们也可以使用 chroot 来切换到一个临时的系统。
容器的概念
容器是镜像的运行实体
容器运行这真正的应用进程
容器有初建、运行、停止、暂停和删除五种状态
在容器内部,无法看到主机上的进程、环境变量、网络等信息
Docker Hub
Docker Hub是官方公开镜像仓库,有引用或者操作系统的官方镜像,还有很多组织和个人开发的镜像供我们免费存放、下载、研究和使用
文章作者 lyr
上次更新 2022-03-11