go语言源码赏析
[[go技术概述_源码赏析0]]
go数据结构要点
-
一个结构体占用空间大小与下面那种有关?
- 成员本身大小
- 成员对齐系数
- 系统字长
-
go字符串中,每个字符占用多少字节
- 1字节
- 3字节
- 4字节
解析: go字符串采用utf-8编码,一个字符1-4字节
-
go的 map是什么数据结构?
- b+树
- 开放寻址hash表
- 拉链法hash表
go map采用拉链hash,特征是 哈希桶(bucket)
-
空结构体的地址任何时候都是 zerobase(x)
错,空结构体是其他结构体成员时,地址跟随其他兄弟成员
-
空接口就是 nil接口
空接口有2个成员,分别是 数据和类型,当数据和类型都不存在时候,才是 nil接口
sizeof 判断类型大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
package main
import (
"fmt"
"unsafe"
)
type A interface{}
func echo(a ...interface{}) {
for _, v := range a {
fmt.Printf("%T -> %+v\n", v, unsafe.Sizeof(v))
}
}
func main() {
var a A
fmt.Printf("%+v", unsafe.Sizeof(a))
fmt.Printf("%+v\n", unsafe.Sizeof(&a))
fmt.Printf("%+v\n", unsafe.Sizeof(uint(0)))
fmt.Printf("%+v\n", unsafe.Sizeof(int(0)))
fmt.Printf("%+v\n", unsafe.Sizeof(int32(0)))
fmt.Printf("%+v\n", unsafe.Sizeof(int64(0)))
// 如果用interface的话,最后全部都是 大小为16字节
echo(a, &a, uint(0), int(0), int32(0), int64(0))
}
|
go 实现hashSet同时节省内存
使用 channel,如果我们只想 发送一个信号的话,我们用 int 占用8个字节,用int32占用4个字节,int64占用8字节,用 bool 占用一个字节,byte 占用一个字节
用 struct{} 空结构体更加节省内存。
空结构体节省内存
- 空结构体地址相同(不被包含在其他结构体中时)
- 空结构体主要是为了节约内存
- 结合 map (可以实现hashset )
- 结合 channel (当作纯信号)
- go中部分数据长度与系统字长有关
- 空结构体不占用空间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
package main
import (
"fmt"
"unsafe"
)
func main() {
a := make(chan struct{})
// chan struct {} 空结构体不占用任何内存,比 chan bool 更轻量,建议用 struct{}
m := make(map[string]struct{})
m["a"] = struct{}{} // 空结构体不占用内存
fmt.Printf("%+v\n", m)
fmt.Printf("%+v\n", a)
fmt.Printf("%+v %v\n", unsafe.Sizeof(byte(1)), unsafe.Sizeof(false))
var b = struct{}{}
var c = struct{}{}
fmt.Printf("%p %p", &b, &c) //得出结论:空结构体地址都相同,类似NULL,但是不是0,而是某块地址
}
|
字符串的内存占用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
package main
import (
"fmt"
"unsafe"
)
func main() {
a := "hello"
b := "world......"
fmt.Printf("%v %v\n", unsafe.Sizeof(a), unsafe.Sizeof(b))
//结果是两个都是 16
}
|
原因:看 src\runtime\string.go 的237行
1
2
3
4
5
|
type stringStruct struct {
str unsafe.Pointer
len int
}
|
stringStruct 就是 string真实的样子
- 字符串本质是一个结构体
- Data指针指向底层 Byte 数组
- Len表示 Byte数组的长度? 字符个数?
src/reflect/value.go 反射包里面也有一个一模一样的
1
2
3
4
5
6
7
8
9
10
|
// StringHeader is the runtime representation of a string.
// It cannot be used safely or portably and its representation may
// change in a later release.
// Moreover, the Data field is not sufficient to guarantee the data
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
type StringHeader struct {
Data uintptr
Len int
}
|
uintptr 类型是最底层的指针表示,我们可以把字符串转成 StringHeader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
a := "hello你"
b := "world......"
fmt.Printf("%v %v\n", unsafe.Sizeof(a), unsafe.Sizeof(b))
//结果是两个都是 16
sh := (*reflect.StringHeader)(unsafe.Pointer(&a))
fmt.Printf("%+v\n", sh)
fmt.Printf("%v %v\n", sh.Data, sh.Len)
}
|
sh.Len == 8 我们可以知道, 其中 汉字 占用了3个字节,字母只占用一个字节
go使用的是 Utf8编码,Len存储的是byte数组的长度 ,而不是字符串的长度
utf-8是变长编码,有可能要3个字节才能表示一个中文。
Unicode介绍
- 一种统一的字符集
- 囊括159种文字的 144679个字符
- 14万个字符 至少需要3个字节表示
- utf8是Unicode的一种变长格式
- 128个US-ASCII字符只需要一个字节编码
遍历字符串的方法
- 对字符串使用len方法得到的是字节数,不是字符数
- 对字符串直接使用下标访问,得到的是字节
- 字符串被range遍历的时候,会解析为 rune也就是 int32的类型的字符,占用4字节
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
package main
import (
"fmt"
)
func main() {
a := "hello你"
// b := "world......"
for i := 0; i < len(a); i++ {
fmt.Printf("%v: %v\n", i, a[i])
}
fmt.Printf("-----\n")
for i, c := range a {
fmt.Printf("%v->%+v\n", i, c)
}
fmt.Printf("-----\n")
}
|
字符串解码算法源码
runtime\utf8.go 有个 decoderune 和 encoderune的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
func decoderune(s string, k int) (r rune, pos int) {
pos = k
if k >= len(s) {
return runeError, k + 1
}
s = s[k:]
switch {
case t2 <= s[0] && s[0] < t3:
// 0080-07FF two byte sequence
if len(s) > 1 && (locb <= s[1] && s[1] <= hicb) {
r = rune(s[0]&mask2)<<6 | rune(s[1]&maskx)
pos += 2
if rune1Max < r {
return
}
}
case t3 <= s[0] && s[0] < t4:
// 0800-FFFF three byte sequence
if len(s) > 2 && (locb <= s[1] && s[1] <= hicb) && (locb <= s[2] && s[2] <= hicb) {
r = rune(s[0]&mask3)<<12 | rune(s[1]&maskx)<<6 | rune(s[2]&maskx)
pos += 3
if rune2Max < r && !(surrogateMin <= r && r <= surrogateMax) {
return
}
}
case t4 <= s[0] && s[0] < t5:
// 10000-1FFFFF four byte sequence
if len(s) > 3 && (locb <= s[1] && s[1] <= hicb) && (locb <= s[2] && s[2] <= hicb) && (locb <= s[3] && s[3] <= hicb) {
r = rune(s[0]&mask4)<<18 | rune(s[1]&maskx)<<12 | rune(s[2]&maskx)<<6 | rune(s[3]&maskx)
pos += 4
if rune3Max < r && r <= maxRune {
return
}
}
}
return runeError, k + 1
}
// encoderune writes into p (which must be large enough) the UTF-8 encoding of the rune.
// It returns the number of bytes written.
func encoderune(p []byte, r rune) int {
// Negative values are erroneous. Making it unsigned addresses the problem.
switch i := uint32(r); {
case i <= rune1Max:
p[0] = byte(r)
return 1
case i <= rune2Max:
_ = p[1] // eliminate bounds checks
p[0] = t2 | byte(r>>6)
p[1] = tx | byte(r)&maskx
return 2
case i > maxRune, surrogateMin <= i && i <= surrogateMax:
r = runeError
fallthrough
case i <= rune3Max:
_ = p[2] // eliminate bounds checks
p[0] = t3 | byte(r>>12)
p[1] = tx | byte(r>>6)&maskx
p[2] = tx | byte(r)&maskx
return 3
default:
_ = p[3] // eliminate bounds checks
p[0] = t4 | byte(r>>18)
p[1] = tx | byte(r>>12)&maskx
p[2] = tx | byte(r>>6)&maskx
p[3] = tx | byte(r)&maskx
return 4
}
}
|
字符串切分:
1
2
|
s := string([]rune(b)[:3])
// 取前3个数
|
切片结构分析
在 runtime/slice.go 下面
1
2
3
4
5
6
7
8
9
10
11
12
13
|
type slice struct {
array unsafe.Pointer
len int
cap int
}
// A notInHeapSlice is a slice backed by go:notinheap memory.
type notInHeapSlice struct {
array *notInHeap
len int
cap int
}
|
reflect/value.go 下面有一个 sliceHeader
1
2
3
4
5
6
|
// a separate, correctly typed pointer to the underlying data.
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
|
切片的几种创建方法
- 根据数组创建
arr[0:3] or slice[0:3]
- 字面量,编译时插入创建数组的代码
slice := []int{1,2,3}
- make: 运行时创建数组
slice := make([]int,10)
切片的行为
切片的追加
- 扩容时,编译时转为调用
runtime.growslice() 方法
- 如果期望容量大于当前容量的两倍就使用期望容量
- 如果当前切片的长度小于 1024 ,将容量翻倍
- 如果当前切片长度大于 1024 ,每次增加 25%
- 切片扩容时,并发不安全,注意切片并发加锁 (多线程不安全)
- 新追加进来的元素,由于cpu具有多级缓存,可能老的协程看到的长度是原来的长度,实际长度已经增加了
切片扩容源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
|
func growslice(et *_type, old slice, cap int) slice {
if raceenabled {
callerpc := getcallerpc()
racereadrangepc(old.array, uintptr(old.len*int(et.size)), callerpc, abi.FuncPCABIInternal(growslice))
}
if msanenabled {
msanread(old.array, uintptr(old.len*int(et.size)))
}
if asanenabled {
asanread(old.array, uintptr(old.len*int(et.size)))
}
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve old.array in this case.
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
newcap := old.cap
//默认是 oldcap*2
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap < threshold {
//如果 cap < 256 ,newcap = 2*oldcap
newcap = doublecap
} else {
//如果 cap >= 256 ,newcap = (oldcap + 3*256) /4
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
// 该公式让切片 的长度是原切片的 [1.25,2]倍左右,旧数组越大,就越接近1.25
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
//如果整数溢出了,newcap 不变
newcap = cap
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For goarch.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == goarch.PtrSize:
lenmem = uintptr(old.len) * goarch.PtrSize
newlenmem = uintptr(cap) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if goarch.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
// The check of overflow in addition to capmem > maxAlloc is needed
// to prevent an overflow which can be used to trigger a segfault
// on 32bit architectures with this example program:
//
// type T [1<<27 + 1]int64
//
// var d T
// var s []T
//
// func main() {
// s = append(s, d, d, d, d)
// print(len(s), "\n")
// }
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
// The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length).
// Only clear the part that will not be overwritten.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in old.array since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem-et.size+et.ptrdata)
}
}
memmove(p, old.array, lenmem)
return slice{p, old.len, newcap}
}
|
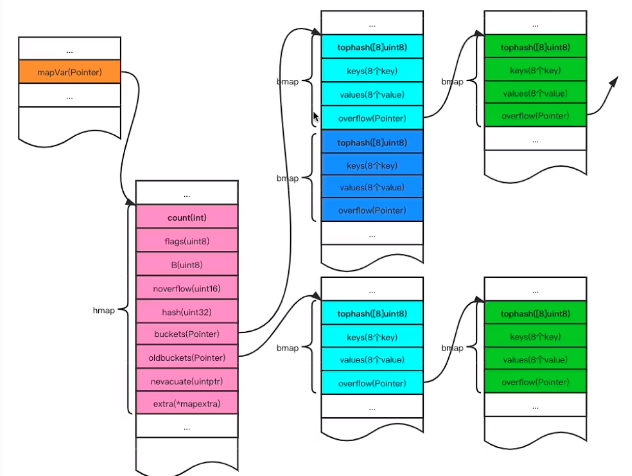
hashMap实现原理
golang 采用类似java的拉链法实现的 hashMap
runtime/map.go 下面有个 hmap
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
|
buckets 的数据结构是 bmap
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
|
1
2
3
4
5
6
7
|
m := make(map[string]int, 3)
m["1"] = 2
m["2"] = 2
m["3"] = 2
fmt.Printf("%+v\n", m)
// go build -gcflags -S main.go
// 我们可以看到 call runtime.makemap(SB) 的汇编
|
makemap 源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
// m:= make(map[string]int,10) ,通过 make创建,会调用这个方法
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
//根据我们传入的 size来计算 B,也就是桶的大小
h.B = B
// allocate initial hash table
// if B == 0, the buckets field is allocated lazily later (in mapassign)
// If hint is large zeroing this memory could take a while.
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
|
字面量初始化
1
2
3
4
5
6
|
hash := map[string]int {
"1":2,
"2":2,
"3":2,
}
fmt.Printf("%+v\n",hash)
|
这种做法最终也是调用的 makemap 方法
相当于:
当元素少于25个的时候,会直接静态调用
1
2
3
4
5
|
m := make(map[string]int, 3)
m["1"] = 2
m["2"] = 2
m["3"] = 2
fmt.Printf("%+v\n", m)
|
当元素多余25个的时候,会转循环复制
1
2
3
4
5
|
hash := map[string]int {
"1":1,
//...
"100":100,
}
|
1
2
3
4
5
6
|
hash := make(map[string]int,100)
k := []string{"1",...,"100"}
v := []int{1,...,100}
for i,s := range k {
hash[s] = v[i]
}
|
hashMap总结
- go使用拉链法实现 hashMap
- 每个桶中存储键哈希的前8位
- 桶超出8个数据,就会存储到溢出桶中
参考文章
参考笔记
map扩容原理
- map溢出桶太多的时候导致性能严重下降
- 为了保证map访问的高效性,需要扩容,减少hash冲突
runtime.mapassign 可能会触发扩容的情况
- 装载因子超过6.5 (平均每个槽6.5个key)
- 使用太多溢出桶(溢出桶超过了普通桶)
hashMap线程安全问题
一旦并发读写,就会fatal 异常
- map的读写有并发问题
- A协程在桶中读数据时,B协程驱逐了这个桶
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
package main
func main() {
m := make(map[int]int)
go func() {
for {
_ = m[1]
}
}()
go func() {
for {
m[2] = 2
}
}()
select {}
}
|
1
2
3
|
fatal error: concurrent map read and map write
goroutine 5 [running]:
|
线程安全的Map
sync.Map是一个结构体 在 sync包 map.go下面
参考博客1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
type Map struct {
mu Mutex
// read contains the portion of the map's contents that are safe for
// concurrent access (with or without mu held).
//
// The read field itself is always safe to load, but must only be stored with
// mu held.
//
// Entries stored in read may be updated concurrently without mu, but updating
// a previously-expunged entry requires that the entry be copied to the dirty
// map and unexpunged with mu held.
read atomic.Value // readOnly
// dirty contains the portion of the map's contents that require mu to be
// held. To ensure that the dirty map can be promoted to the read map quickly,
// it also includes all of the non-expunged entries in the read map.
//
// Expunged entries are not stored in the dirty map. An expunged entry in the
// clean map must be unexpunged and added to the dirty map before a new value
// can be stored to it.
//
// If the dirty map is nil, the next write to the map will initialize it by
// making a shallow copy of the clean map, omitting stale entries.
dirty map[any]*entry
// misses counts the number of loads since the read map was last updated that
// needed to lock mu to determine whether the key was present.
//
// Once enough misses have occurred to cover the cost of copying the dirty
// map, the dirty map will be promoted to the read map (in the unamended
// state) and the next store to the map will make a new dirty copy.
misses int
}
// readOnly is an immutable struct stored atomically in the Map.read field.
type readOnly struct {
m map[any]*entry
amended bool // true if the dirty map contains some key not in m.
}
|
- sync.Map 使用了2个map,分离了扩容问题
- 不会引发扩容的操作(查、改) 使用 read map
- 可能引发扩容的操作 使用 dirty map
golang 接口
iface原理,在 src\runtime\runtime2.go 里面定义的结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// ../cmd/compile/internal/reflectdata/reflect.go:/^func.WriteTabs.
type itab struct {
inter *interfacetype
_type *_type
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
}
type iface struct {
tab *itab
data unsafe.Pointer
}
|
接口 是 itab 里面的, data 是指向实现接口的结构体的指针
接口值的底层表示:
- 接口数据使用
runtime.iface 表示
iface 记录了数据的地址iface 也记录了接口类型信息和实现的方法
结构体和指针实现接口
|
结构体实现接口 |
结构体指针实现接口 |
| 结构体初始化变量 |
通过 |
不通过 |
| 结构体指针初始化变量 |
通过 |
通过 |
空接口类型
iface里面存有类型和数据,你可以用printf %T ,%v等打印出来
eface 是 empty interface{}, eface有个单独的结构
1
2
3
4
5
|
type eface struct {
_type *_type
data unsafe.Pointer
}
|
1
2
3
|
func K(a interface{}) {
//a可以放入任何的值
}
|
空接口的值
- runtime.eface 结构体
- 空接口底层不是普通接口
- 空接口可以承载任何数据
空接口的用途
其实 空接口就是编译的时候直接编译器将数据转为 eface来进行传参
总结
- go隐式接口更加方便系统扩展和重构
- 结构体和指针都可以实现接口
- 空接口可以承载任何类型的数据
nil,空接口,空结构体区别
builtin包里面定义了
1
2
3
4
|
// nil is a predeclared identifier representing the zero value for a
// pointer, channel, func, interface, map, or slice type.
var nil Type // Type must be a pointer, channel, func, interface, map, or slice type
|
go里面定义了 nil其实是个变量来的,Type可以是个指针,channel,方法 ,map,func,切片等,可以是任意一种类型的空
1
2
3
4
5
6
7
8
9
10
11
|
package main
import "fmt"
func main() {
var mp map[string]int
var a *int
fmt.Printf("%v\n", mp == nil)
fmt.Printf("%+v\n", a == nil)
}
|
- nil是空,当不是空指针
- nil是6种类型的 “零值”
- nil永远不能和结构体比较,每种类型的nil也不相同
- 空结构体是go中比较特殊的类型
- 空结构体的值不是nil,但是和nil都是 zerobase
- 空接口也不一定是 nil接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
package main
import "fmt"
func main() {
var a interface{}
var b interface{}
var c *int
fmt.Printf("%+v\n", a == nil)
fmt.Printf("%+v\n", b == nil)
fmt.Printf("%+v\n", a == b)
fmt.Printf("%+v\n", a == c)
// fmt.Printf("%v\n", b == nil)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
package main
import "fmt"
func main() {
var a interface{}
// var b interface{}
var c *int
fmt.Printf("%+v\n", a == nil)
a = c
// a底层是 eface结构体
// c底层是 iface结构体,因此 现在 a!=nil
fmt.Printf("%+v\n", a == nil)
fmt.Printf("%+v\n", c == nil)
}
|
- nil是多个类型的零值,或空值
- 空结构体的指针和值都不是nil
- 空接口零值是nil,一旦有了类型信息就不是nil
内存对齐优化
下面代码最后结果都是8
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package main
import (
"fmt"
"unsafe"
)
func main() {
var a struct {
a, b int32
}
var b struct {
a int16
b int32
}
var c struct {
b struct{}
z struct{}
}
fmt.Printf("%+v\n", unsafe.Sizeof(a))
fmt.Printf("%+v\n", unsafe.Sizeof(b))
fmt.Printf("aligna %v,alignb %v\n", unsafe.Alignof(a), unsafe.Alignof(b))
// 空结构体长度是0
fmt.Printf("%+v\n", unsafe.Sizeof(struct{}{}))
fmt.Printf("%+v\n", unsafe.Sizeof(c))
// fmt.Printf("%+v\n", unsafe.Sizeof(nil))
}
|
我们知道64位cpu,就是按8字节去读取的,cpu访问内存按照字长读取,所以一般会给结构体加 padding凑整,优化cpu读取效率
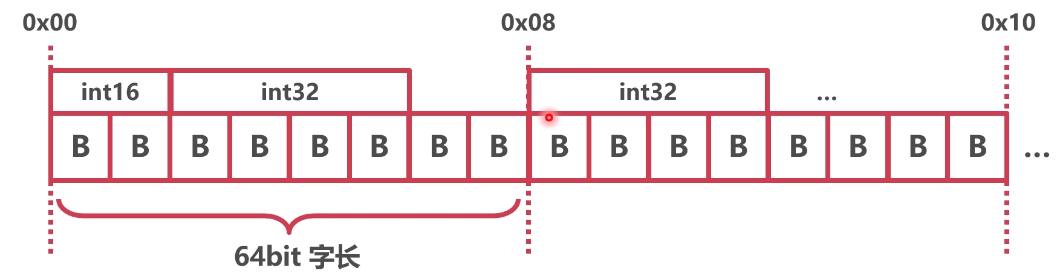
- 空结构体的size是0,不占用空间
- 结合map实现 hashset
- 结合channel用于发送信号
- 基本类型对齐考虑系数
- 结构体既需要内部对齐,有需要外部填充对齐
- 空结构体作为最后一个成员,需要填充对齐

