1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
|
// Tries to steal from other P's, get g from local or global queue, poll network.
func findrunnable() (gp *g, inheritTime bool) {
_g_ := getg()
// The conditions here and in handoffp must agree: if
// findrunnable would return a G to run, handoffp must start
// an M.
top:
_p_ := _g_.m.p.ptr()
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
if _p_.runSafePointFn != 0 {
runSafePointFn()
}
now, pollUntil, _ := checkTimers(_p_, 0)
if fingwait && fingwake {
if gp := wakefing(); gp != nil {
ready(gp, 0, true)
}
}
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
// local runq
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// global runq
if sched.runqsize != 0 {
lock(&sched.lock)
// 从全局队列获取 g
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
// Poll network.
// This netpoll is only an optimization before we resort to stealing.
// We can safely skip it if there are no waiters or a thread is blocked
// in netpoll already. If there is any kind of logical race with that
// blocked thread (e.g. it has already returned from netpoll, but does
// not set lastpoll yet), this thread will do blocking netpoll below
// anyway.
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
// Spinning Ms: steal work from other Ps.
//
// Limit the number of spinning Ms to half the number of busy Ps.
// This is necessary to prevent excessive CPU consumption when
// GOMAXPROCS>>1 but the program parallelism is low.
procs := uint32(gomaxprocs)
if _g_.m.spinning || 2*atomic.Load(&sched.nmspinning) < procs-atomic.Load(&sched.npidle) {
if !_g_.m.spinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
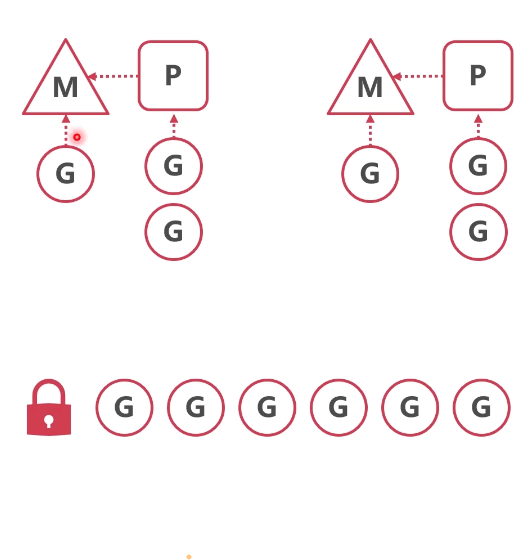
// stealWork: 工作窃取算法: 如果全局队列没有任务,就尝试从其他线程本地队列中获取任务执行
gp, inheritTime, tnow, w, newWork := stealWork(now)
now = tnow
if gp != nil {
// Successfully stole.
return gp, inheritTime
}
if newWork {
// There may be new timer or GC work; restart to
// discover.
goto top
}
if w != 0 && (pollUntil == 0 || w < pollUntil) {
// Earlier timer to wait for.
pollUntil = w
}
}
// We have nothing to do.
//
// If we're in the GC mark phase, can safely scan and blacken objects,
// and have work to do, run idle-time marking rather than give up the
// P.
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(_p_) {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
_p_.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
// wasm only:
// If a callback returned and no other goroutine is awake,
// then wake event handler goroutine which pauses execution
// until a callback was triggered.
gp, otherReady := beforeIdle(now, pollUntil)
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
if otherReady {
goto top
}
// Before we drop our P, make a snapshot of the allp slice,
// which can change underfoot once we no longer block
// safe-points. We don't need to snapshot the contents because
// everything up to cap(allp) is immutable.
allpSnapshot := allp
// Also snapshot masks. Value changes are OK, but we can't allow
// len to change out from under us.
idlepMaskSnapshot := idlepMask
timerpMaskSnapshot := timerpMask
// return P and block
lock(&sched.lock)
if sched.gcwaiting != 0 || _p_.runSafePointFn != 0 {
unlock(&sched.lock)
goto top
}
if sched.runqsize != 0 {
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
return gp, false
}
if releasep() != _p_ {
throw("findrunnable: wrong p")
}
pidleput(_p_)
unlock(&sched.lock)
// Delicate dance: thread transitions from spinning to non-spinning
// state, potentially concurrently with submission of new work. We must
// drop nmspinning first and then check all sources again (with
// #StoreLoad memory barrier in between). If we do it the other way
// around, another thread can submit work after we've checked all
// sources but before we drop nmspinning; as a result nobody will
// unpark a thread to run the work.
//
// This applies to the following sources of work:
//
// * Goroutines added to a per-P run queue.
// * New/modified-earlier timers on a per-P timer heap.
// * Idle-priority GC work (barring golang.org/issue/19112).
//
// If we discover new work below, we need to restore m.spinning as a signal
// for resetspinning to unpark a new worker thread (because there can be more
// than one starving goroutine). However, if after discovering new work
// we also observe no idle Ps it is OK to skip unparking a new worker
// thread: the system is fully loaded so no spinning threads are required.
// Also see "Worker thread parking/unparking" comment at the top of the file.
wasSpinning := _g_.m.spinning
if _g_.m.spinning {
_g_.m.spinning = false
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("findrunnable: negative nmspinning")
}
// Note the for correctness, only the last M transitioning from
// spinning to non-spinning must perform these rechecks to
// ensure no missed work. We are performing it on every M that
// transitions as a conservative change to monitor effects on
// latency. See golang.org/issue/43997.
// Check all runqueues once again.
_p_ = checkRunqsNoP(allpSnapshot, idlepMaskSnapshot)
if _p_ != nil {
acquirep(_p_)
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
goto top
}
// Check for idle-priority GC work again.
_p_, gp = checkIdleGCNoP()
if _p_ != nil {
acquirep(_p_)
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
// Run the idle worker.
_p_.gcMarkWorkerMode = gcMarkWorkerIdleMode
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
// Finally, check for timer creation or expiry concurrently with
// transitioning from spinning to non-spinning.
//
// Note that we cannot use checkTimers here because it calls
// adjusttimers which may need to allocate memory, and that isn't
// allowed when we don't have an active P.
pollUntil = checkTimersNoP(allpSnapshot, timerpMaskSnapshot, pollUntil)
}
// Poll network until next timer.
if netpollinited() && (atomic.Load(&netpollWaiters) > 0 || pollUntil != 0) && atomic.Xchg64(&sched.lastpoll, 0) != 0 {
atomic.Store64(&sched.pollUntil, uint64(pollUntil))
if _g_.m.p != 0 {
throw("findrunnable: netpoll with p")
}
if _g_.m.spinning {
throw("findrunnable: netpoll with spinning")
}
delay := int64(-1)
if pollUntil != 0 {
if now == 0 {
now = nanotime()
}
delay = pollUntil - now
if delay < 0 {
delay = 0
}
}
if faketime != 0 {
// When using fake time, just poll.
delay = 0
}
list := netpoll(delay) // block until new work is available
atomic.Store64(&sched.pollUntil, 0)
atomic.Store64(&sched.lastpoll, uint64(nanotime()))
if faketime != 0 && list.empty() {
// Using fake time and nothing is ready; stop M.
// When all M's stop, checkdead will call timejump.
stopm()
goto top
}
lock(&sched.lock)
_p_ = pidleget()
unlock(&sched.lock)
if _p_ == nil {
injectglist(&list)
} else {
acquirep(_p_)
if !list.empty() {
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
goto top
}
} else if pollUntil != 0 && netpollinited() {
pollerPollUntil := int64(atomic.Load64(&sched.pollUntil))
if pollerPollUntil == 0 || pollerPollUntil > pollUntil {
netpollBreak()
}
}
stopm()
goto top
}
|