go 反射使用
大多数编程语言系统都是类似的,会有类型声明,实际类型之类的分别
go 的反射里面,一个实例可以看出两个部分
| 名字 |
对应 |
| 值信息 |
reflect.Value |
| 类型信息 |
reflect.Type |
- reflect.Value 用于操作值,部分值可以用反射修改
- reflect.Type 用于操作类信息,类信息只能读取
reflect.Type 可以通过 reflect.Value 得到,反过来则不行
reflect Kind
reflect 包有一个假设,你必须知道你操作的是什么 Kind
Kind: kind 是一个枚举值,用来判断操作的对应类型,例如指针,是否数组是否切片等。
用 reflect方法,你调用不对就会panic
下面方法在 reflect.Type 里面 ,这几个都有对应的Kind ,用错会panic
NumField() intNumIn() intNumOut() int
1
2
3
4
5
6
7
8
9
10
11
|
// NumField返回一个结构类型的字段数。
// 如果该类型的Kind不是Struct,它就会陷入恐慌。
NumField() int
// NumIn 返回一个函数类型的输入参数数。
// 如果该类型的Kind不是Func,它就会陷入恐慌。
NumIn() int
// NumOut 返回一个函数类型的输出参数数。
// 如果该类型的Kind不是Func,它就会陷入恐慌。
NumOut() int
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
|
// 不是所有的方法都适用于所有种类的类型。限制条件。
// 如果有的话,会在每个方法的文档中注明。
// 在调用特定类型的方法之前,使用Kind方法找出类型的种类。
// 调用特定种类的方法。调用一个方法
// 调用与类型不相称的方法会引起运行时的恐慌。
//
// 类型的值是可以比较的,比如用==运算符。
// 所以它们可以被用作地图键。
// 如果两个类型值代表相同的类型,它们就是相等的。
Type Type interface {
// 适用于所有类型的方法。
// Align返回一个类型的值在内存中分配时的字节数。
// 这个类型的值在内存中分配时的字节数。
Align() int
// 字段对齐(FieldAlign)返回该类型的值在结构中作为字段时的字节数。
// 当作为结构中的一个字段使用时,返回该类型值的字节数。
FieldAlign() int
// 方法返回该类型的方法集中的第i个方法。
// 如果i不在[0, NumMethod()]的范围内,它就会崩溃。
//
// 对于非接口类型T或*T,返回Method的Type和Func
// 字段描述一个函数,其第一个参数是接收者。
// 并且只有导出的方法可以被访问。
//
// 对于一个接口类型,返回的Method的Type字段给出了
// 对于一个接口类型,返回的Method的Type字段给出了方法的签名,但没有接收者,Func字段为nil。
//
// 方法的排序是按词汇学顺序进行的。
Method(int) Method
// Method(int) Method(int) MethodByName返回该类型中具有该名称的方法。
// 方法集,以及一个表示是否找到该方法的布尔值。
//
// 对于非接口类型T或*T,返回Method的Type和Func
// 字段描述一个函数,其第一个参数是接收者。
//
// 对于一个接口类型,返回的Method的Type字段给出了方法的签名。
// 对于接口类型,返回的Method的Type字段给出了方法的签名,没有接收器,Func字段为nil。
MethodByName(string) (Method, bool)
// NumMethod返回使用Method可以访问的方法的数量。
//
// 注意,NumMethod只计算接口类型的未输出方法。
NumMethod() int
// 对于定义的类型,Name 返回该类型在其包中的名称。
// 对于其他(非定义)类型,它返回空字符串。
Name() string
// PkgPath 返回定义类型的包路径,也就是导入路径。
// 即唯一标识该包的导入路径,如 "encoding/base64"。
// 如果该类型是预先声明的(字符串,错误)或者没有定义(*T,struct{},
// []int, 或者A是一个非定义类型的别名),包的路径
// 将是一个空字符串。
PkgPath() string
// 大小返回存储给定类型的值所需的字节数。
// 一个给定类型的值;它类似于unsafe.Sizeof.
Size() uintptr
// String 返回该类型的字符串表示法。
// 字符串表示可以使用缩短的包名
// (例如,base64而不是 "encoding/base64"),并且不保证在不同类型中是唯一的。
// 类型之间不保证是唯一的。为了测试类型的一致性。
// 直接比较Types。
String() string
// Kind返回该类型的具体种类。
Kind() Kind
// Implements报告该类型是否实现了接口类型u。
Implements(u Type) bool
// AssignableTo 报告该类型的值是否可以被分配给u类型。
AssignableTo(u Type) bool
// ConvertibleTo 报告该类型的值是否可以转换为u类型。
// 即使ConvertibleTo返回true,转换仍然可能发生恐慌。
// 例如,一个[]T类型的片断可以转换为*[N]T。
// 但如果它的长度小于N,转换就会发生恐慌。
ConvertibleTo(u Type) bool
// Comparable报告此类型的值是否可以比较。
// 即使Comparable返回true,比较仍然可能发生恐慌。
// 例如,接口类型的值是可比较的。
// 但是如果他们的动态类型不具有可比性,那么比较就会出现恐慌。
Comparable() bool
// 只适用于某些类型的方法,取决于Kind。
// 每种类型所允许的方法是。
//
// Int*, Uint*, Float*, Complex*: Bits
// 数组。Elem, Len
// 陈。ChanDir, Elem
// Func: In, NumIn, Out, NumOut, IsVariadic.
// 地图。键,元素
// 指针。指针: Elem
// 切片。Elem
// 结构。Field, FieldByIndex, FieldByName, FieldByNameFunc, NumField
// Bits返回类型的大小,单位为比特。
// 如果该类型的Kind不是下列之一,它就会惊慌失措
// 有大小的Int、Uint、Float或Complex类型之一。
Bits() int
// ChanDir 返回一个通道类型的方向。
// 如果该类型的Kind不是Chan,它就会慌乱。
ChanDir() ChanDir
// IsVariadic 报告一个函数类型的最终输入参数是否
// 是一个"... "参数。如果是,t.In(t.NumIn() - 1)返回该参数的
//隐含的实际类型[]T。
//
// 为了具体说明,如果t代表func(x int, y ... float64),那么
//
// t.NumIn() == 2
// t.In(0)是 "int "的反射类型。
// t.In(1)是"[]float64 "的反射.类型。
// t.IsVariadic() == true
//
// 如果类型的Kind不是Func.IsVariadic,那么IsVariadic就会恐慌。
IsVariadic() bool
// Elem返回一个类型的元素类型。
// 如果该类型的Kind不是Array、Chan、Map、Pointer或Slice,它就会报警。
Elem() Type
// Field返回一个结构类型的第i个字段。
// 如果该类型的Kind不是Struct,它就会陷入恐慌。
// 如果i不在[0, NumField()]范围内,它就会崩溃。
Field(i int) StructField
// FieldByIndex返回对应于索引序列的嵌套字段。
// 对应于索引序列。它等同于对每个索引i连续调用Field
// 对每个索引i连续地调用。
// 如果类型的Kind不是Struct,它就会慌乱。
FieldByIndex(index []int) StructField
// FieldByName返回具有给定名称的结构字段。
// 和一个表示是否找到该字段的布尔值。
FieldByName(name string) (StructField, bool)
// FieldByNameFunc 返回带有名称的结构字段。
// 满足匹配函数的结构字段,并以一个布尔值表示是否
// 该字段被找到。
//
// FieldByNameFunc考虑的是结构本身的字段,然后是任何嵌入的字段。
// 然后是任何嵌入结构中的字段,按照广度优先的顺序。
// 在包含一个或多个字段的最浅嵌套深度时停止。
// 含有一个或多个满足匹配函数的字段的最浅嵌套深度。如果该深度的多个字段
// 满足匹配函数,它们会相互抵消
// 并且FieldByNameFunc不返回匹配。
// 这种行为反映了Go对包含内嵌字段的结构中的名称查询的处理。
// 包含内嵌字段的结构中的名称查询。
FieldByNameFunc(match func(string) bool) (StructField, bool)
// In返回一个函数类型的第i个输入参数的类型。
// 如果该类型的Kind不是Func,它就会恐慌。
// 如果i不在[0, NumIn()]范围内,它就会崩溃。
In(i int) Type
// Key返回map类型的键类型。
// 如果该类型的Kind不是Map,它就会崩溃。
Key() Type
// Len返回一个数组类型的长度。
// 如果该类型的Kind不是Array,它就会崩溃。
Len() int
// NumField 返回一个结构类型的字段数。
// 如果该类型的Kind不是Struct,它就会崩溃。
NumField() int
// NumIn 返回一个函数类型的输入参数数。
// 如果该类型的Kind不是Func,它就会陷入恐慌。
NumIn() int
// NumOut 返回一个函数类型的输出参数数。
// 如果该类型的Kind不是Func,它就会陷入恐慌。
NumOut() int
// Out 返回一个函数类型的第i个输出参数的类型。
// 如果该类型的Kind不是Func,它就会恐慌。
// 如果i不在[0, NumOut()]的范围内,它就会崩溃。
Out(i int) Type
common() *rtype
uncommon() *uncommonType
}
|
使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type User struct {
Name string
}
func main() {
// p := NewLimit(10)
v := reflect.ValueOf(&User{})
// 必须要 转结构体,传入指针会报错
k := v.Type()
for i := 0; i < k.Elem().NumField(); i++ {
fmt.Println(i)
}
}
|
用反射设置值
可以用反射来修改一个字段的值。需要
注意的是,修改字段的值之前一定要先
检查 CanSet。
简单来说,就是必须使用结构体指针,
那么结构体的字段才是可以修改的。
当然指针指向的对象也是可以修改的。
Unsafe 操作
要使用unsafe,就要理解go 中一个对象的内存是如何布局的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
package main
import (
"fmt"
"reflect"
)
type User struct {
// 假设
Name string //len=16, 占用2个8字节
age int32 // len=4 --> 后面 4字节空了
Alias []byte //len=24
Address string //len=16,
}
func printOffset(v_ any) {
v := reflect.Indirect(reflect.ValueOf(v_))
k := v.Type()
for i := 0; i < k.NumField(); i++ {
ff := k.Field(i)
fmt.Println(ff.Name, ff.Offset)
}
}
func main() {
printOffset(User{})
}
/*
Name 0
age 16
Alias 24
Address 48
*/
|
字长对齐
按照字长对齐。因为 GO 本身每次访问内存都是按照字节的倍数访问的
uintptr 使用注意
但是 uintptr 可以用于表达相对的量。
例如字段偏移量。这个字段的偏移量是
不管怎么 GC 都不会变的。
如果怕出错,那么就只在进行地址运算
的时候使用 uintptr,其它时候都用
unsafe.Pointer。
学习要点
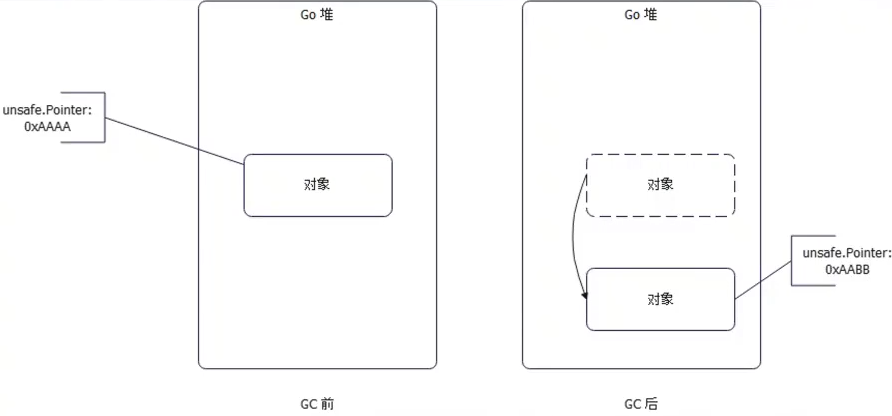
- uintptr 和 unsafe.Pointer 的区别:前者代表的是一个具体的地址,后者代表的是一个逻
辑上的指针。后者在 GC 等情况下,go runtime 会帮你调整,使其永远指向真实存放对
象的地址。
- unsafe 为什么比反射高效?可以简单认为反射帮我们封装了很多 unsafe 的操作,所以
我们直接使用 unsafe 绕开了这种封装的开销。有点像是我们不用 ORM 框架,而是直接
自己写 SQL 执行查询。
- Go 对象是怎么对齐的?按照字长。有些比较恶心的面试官可能要你手动演示如何对齐,
或者写一个对象问你怎么计算对象的大小
- uintptr 和 unsafe.Pointer 的区别:前者代表的是一个具体的地址,后者代表的是一个逻
辑上的指针。后者在 GC 等情况下,go runtime 会帮你调整,使其永远指向真实存放对
象的地址。
unsafe 读写字段
- 读取字段
*(*T)(ptr)
- 写入字段
*(*T)(ptr) = val
- unsafe.Pointer, GO 层面的指针, GC会维护响应的内存值
- uintptr: 直接是数字,代表内存值, 很可能会垃圾回收【修改对象地址后,uintptr 可能有问题, 对象因为垃圾回收被挪走其他的内存位置了】
注意,uintptr 直接记录内存的值是不靠谱的,因为 GC 之后对象有可能被回收获取迁移位置, 这个绝对地址就有问题,但是如果用作对象的相对地址
作为对象的偏移量 是可以这样做的。
1
2
3
4
5
6
|
res := *(*int)(unsafe.Pointer(uintptr(u.entityAddr) + meta.offset))
fmt.Println(res)
*(*int)(unsafe.Pointer(uintptr(u.entityAddr) + meta.offset)) = val
|

