Mutex 实现细节
Mutex 实现细节:
- 自旋尝试,如果快速上锁成功就返回
- 自旋失败并且超过自旋次数,就进入阻塞队列等待唤醒
如果是进入阻塞队列等待这种和语言特性有关,有些是依赖于操作系统线程调度,有些是在用户态自己处理,比如goroutine
1
2
3
4
5
6
7
8
|
// 互斥锁是一种相互排斥的锁。
// Mutex的零值是一个未被锁定的Mutex。
//
// 一个Mutex在第一次使用后不能被复制。
type Mutex struct {
state int32
sema uint32
}
|
理解关键点:
- state就是用来控制锁的核心,所谓加锁,就是把 state修改为某个值, 解锁也是类似
- sema 是用来处理沉睡、唤醒的信号量,依赖于两个 runtime调用:
- runtime_SemacuireMutex: sema 加一并且挂起 goroutine
- runtime_Semrelease: sema 建议并且唤醒sema上等待的一个goroutine
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
// 锁定m。
// 如果锁已经在使用中,调用的goroutine
// 块,直到该mutex可用。
func (m *Mutex) Lock() {
// 快速路径:抓取已解锁的mutex。
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// 慢速路径(概述,以便快速路径可以被内联)。
m.lockSlow()
}
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
for {
// 不要在饥饿模式下旋转,所有权已经移交给了等待者 // 所以我们无论如何都无法获得该突变体。
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
//主动旋转是有意义的。 //尝试设置mutexWoken标志来通知Unlock //不要唤醒其他被阻塞的goroutine。
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state
continue
}
new := old
// 不要试图获取饥饿的mutex,新到达的goroutines必须排队。
if old&mutexStarving == 0 {
new |= mutexLocked
}
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
// 当前的goroutine将mutex切换到饥饿模式。 // 但是如果mutex当前是解锁的,就不要做切换。 // 解锁期望饥饿的mutex有等待者,在这种情况下不会是真的。
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
if awoke {
// 这个goroutine已经从睡眠中被唤醒,//所以我们需要在两种情况下重置这个标志。
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&(mutexLocked|mutexStarving) == 0 {
break // locked the mutex with CAS
}
// 如果我们之前已经在等待,就在队列的前面排队。
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
if old&mutexStarving != 0 {
// 如果这个goroutine被唤醒,并且mutex处于饥饿模式,//所有权被移交给我们,但是mutex处于某种//不一致的状态:mutexLocked没有被设置,我们仍然是//作为服务者。修复这个问题。
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
// 退出饥饿模式。 // 在这里做是很关键的,要考虑等待时间。 // 饥饿模式的效率很低,两个goroutines // 一旦切换mutex // 到饥饿模式,就可以无限地锁定。
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
}
|
正常模式和饥饿模式
- 公平锁饥饿模式: G1 进入队列排队,先来先到,G2拿锁
- 非公平锁正常模式: G2 和 G1 竞争 【G2 一直在sleep ,大概率会让 G1 一直拿到锁,排在队列里面的如果一直拿不到锁就会等待】
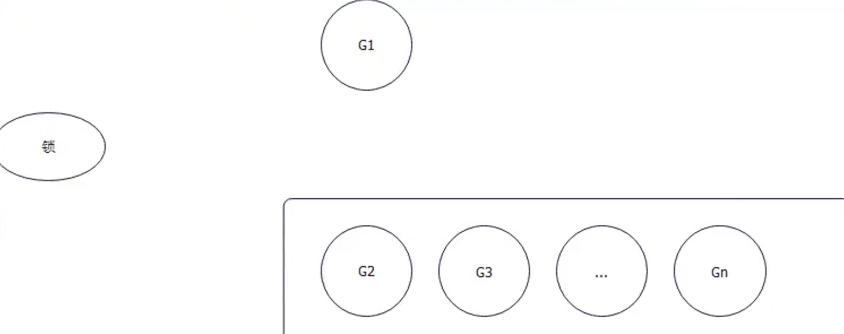
如果每次 G2 都想要拿到锁,结果都被醒来的 G1给抢到了,那么G2 和其他队列中的任务一直排队,就会处于饥饿状态
G2 每次没抢到锁,丢要退回队列头部。 所以如果等待时间超过1ms, 那么锁就会变成饥饿模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
func (m *Mutex) unlockSlow(new int32) {
if(new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlocked mutex of unlocked" )
}
if new&mutexStarving == 0 {
old := new
for {
// 如果没有等待者或者已经有一个goroutine
// 被唤醒或抢到了锁,就不需要唤醒任何人。
// 在饥饿模式下,所有权直接从解锁的goroutine移交给下一个goroutine。
// goroutine到下一个等待者。我们不是这个链条的一部分。
// 因为我们在解锁上面的mutex时没有观察到mutexStarving。
// 所以要离开这个途径。
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// 抢到了唤醒别人的权利。
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else {
// 饥饿模式:将mutex所有权移交给下一个服务器,并让出
// 我们的时间片,以便下一个服务器可以立即开始运行。
// 注意:mutexLocked没有被设置,等待者将在唤醒后设置它。
// 但是如果mutexStarving被设置,mutex仍然被认为是被锁定的。
// 所以新来的goroutines不会获取它。
runtime_Semrelease(&m.sema, true, 1)
}
}
|
Mutex 和 RWMutex 注意场景
- 适用于读多写少的场景
- 写多读少不如直接加锁
- 可以考虑使用函数式写法,如延迟初始化
- RWMutex 和 Mutex都是不可重入的
- 尽可能用 defer 解锁,避免 panic
理解要点
- Mutex公平性: GO 的锁是不公平锁。为什么不涉及为公平锁
- Mutex的两种模式,以及两种模式的切换时机:
- 为什么Mutex设计两种模式? 等价于为什么不设计公平锁
- 如果队列里面有goroutine等待锁,醒来的goroutine有可能拿到锁吗? 大概率。
- Mutex 是不是可重入锁? 不是!
- RWMutex 和 Mutex 有什么区别? 几乎全是写操作用Mutex,其他时候邮箱使用RWMutex
- Mutex 如何做到挂起goroutine的,如何唤醒 goroutine的? 在这个语境下,只需要回答 sema这个字段以及 runtime_Semacquire 和 runtime_Semrelease 两个调用就可以。
Once 使用
sync.Once 一般用于确保某个动作至多执行一次
普遍用于初始化资源,单例模式
sync 包 的工具尽量都用指针,如果复制锁对象可能会报错
1
2
3
4
|
var once sync.Once
func Init() {
once.Do(func() {})
}
|
Once 源码解析
Once没有直接利用读写锁,而是用原值操作扮演读锁角色
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
func (o *Once) Do(f func() ) {
// 注意:这里是Do的一个不正确的实现。
//
// 如果atomic.CompareAndSwapUint32(&o.done, 0, 1) {
// f()
// }
//
// Do保证当它返回时,f已经完成。
// 这个实现不会实现这个保证。
// 如果有两个同时的调用,那么获胜者会
// 调用f,而第二个人将立即返回,而不
//等待第一个人对f的调用完成。
// 这就是为什么慢速路径会返回到一个互斥器,以及为什么
// atomic.StoreUint32必须延迟到f返回之后。
if atomic.LoadUint32(&o.done) == 0 {
// Outlined slow-path to allow inlining of the fast-path.
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
|
Pool 的使用
一般情况下,考虑缓存资源,比如创建的对象,可以使用 sync.Pool
- Sync.Pool 会查看自己是否有资源,有自己返回,没有创建新的
- Sync.Pool 会在GC 的时候释放缓存的资源
一般sync.Pool 是为了复用内存
- 减少内存分配,减少GC压力(主要)
- 扫消耗CPU 资源(内存分配和GC都是CPU 密集操作)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
type User struct {
Name string
}
func (u *User) Reset() {
u.Name = ""
}
func main() {
var p = sync.Pool{
New: func() any {
fmt.Println("init user")
return &User{Name: "helloworld"}
},
}
var u = p.Get().(*User)
fmt.Println(u)
u.Reset()
p.Put(u)
fmt.Println(p.Get())
// p.Put(&User{"helloworld"})
}
|
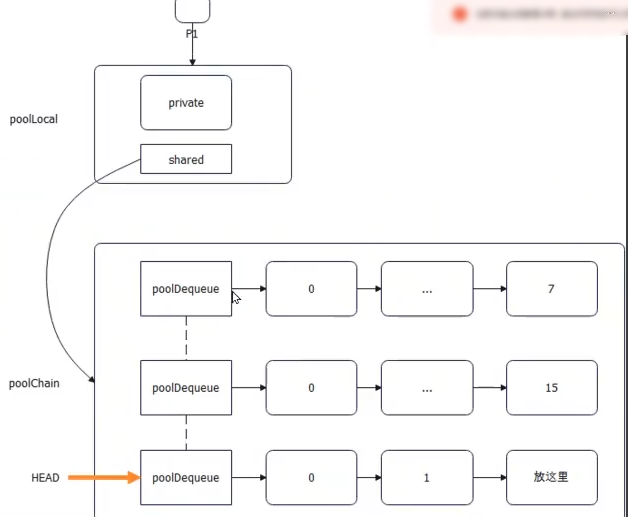
Pool 实现细节
GO 本身的PMG调度模型,
- 每个 p有一个 poolLocal 对象
- 每个 poolLocal 有一个 private 和 shared
- shared 指向 poolChain. poolChain 数据会被别的p偷走
- PoolChain是一个链表+ ring buffer 双重结构
- 整体来说是双向来表
- 单个节点来说,指向ring buffer 。后一个节点 ring buffer 是前一个节点的2倍
ring buffer 优势(实际上也可以说是数组的优势) :
Pool 源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
// 一个Pool可以被多个goroutines同时使用,是安全的。
//
// 池的作用是对已分配但未使用的项目进行缓存,以便以后再使用。
// 减轻了垃圾收集器的压力。也就是说,它使我们能够很容易地
// 构建高效、线程安全的自由列表。然而,它并不适合于所有
// 空闲列表。
//
// 池的一个合适的用途是管理一组临时项目。
// 在一个包的并发独立客户之间默默地共享并可能被重用。
// 包的独立客户端之间默默地共享并可能重复使用。池提供了一种方法来分摊分配的开销
// 在许多客户端之间分摊分配费用。
//
// 一个很好地使用Pool的例子是在fmt包中,它维护一个
// 它维护着一个临时输出缓冲区的动态大小的存储。这个存储空间在以下情况下可以扩展
// 负载下(当许多goroutines积极打印时),存储空间会缩小。
// 沉默不语。
//
// 另一方面,作为短命对象的一部分而维护的空闲列表并不适合使用Pool。
// 不适合使用Pool,因为在这种情况下,开销并不能很好地摊销。
// 因为在这种情况下,开销不能很好地摊销。让这些对象实现自己的
//自由列表。
//
// Pool在第一次使用后不能被复制。
type Pool struct {
noCopy noCopy
local unsafe.Pointer // 本地固定大小的每P池,实际类型为[P]poolLocal , 下一次GC时候 会变成 victim
localSize uintptr // 本地数组的大小。
victim unsafe.Pointer // 来自上一个周期的本地数据 [下一次GC时候释放这个 对象]
victimSize uintptr // 受害者数组的大小
// New可以选择指定一个函数来生成
// 一个值,否则Get将返回nil。
// 它不能与对Get的调用同时改变。
New func() any
}
// 本地per-P池的附录。
type poolLocalInternal struct {
private any // 只能由各P使用。
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
type poolLocal struct {
poolLocalInternal
// 防止在广泛的平台上出现错误的共享,有
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
|
sync.Pool get 的步骤:
- 先看自己有没有 (private)
- 向shared Poolchain 获取
- 别人的 poolChain 里面偷一个
- victim 中即将被释放的对象池中获取
- 前面都获取不到,就创建一个新的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// 获取从池中选择一个任意的项目,将其从
// 池中删除,并将其返回给调用者。
// Get可以选择忽略池子,将其视为空的。
// 调用者不应该假定传递给Put的值和Get返回的值之间有任何关系。
// 由Get返回的值。
//
// 如果Get将返回nil并且p.New不是nil,Get将返回
//调用p.New的结果。
func (p *Pool) Get() any {
if race.Enabled {
race.Disable()
}
l, pid := p.pin()
x := l.private
l.private = nil
if x == nil {
// 尝试弹出本地分片的头部。我们更喜欢//头部,而不是尾部,以便在时间上定位//重用。
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
if x == nil && p.New != nil {
x = p.New()
}
return x
}
|
正常情况下,设计 Pool都要容量和淘汰问题 基本类似于缓存:
- 我们希望控制 Pool的内存消耗量
- 这个前提下我们要考虑淘汰量
sync.Pool 完全依赖于GC,用户没法控制其生命周期
GC 过程很简单:
- locals 会被挪到 victim (缓刑)
- 而原来的 victim 会直接被 GC free掉
复活:
如果victim 对象被再次使用,就会丢回locals,避免下一次GC回收对象
优点:
防止GC引发性能抖动问题
为了减小并发中锁的竞争,sync.pool为每个P(对象cpu线程)分配一个子池子poolLocal,每个poolLocal有private对象和shared共享列表对象,private对象只有对应的P可访问,无需加锁, shared共享列表对象可被其它P共享,需要加锁。
Poolchain 原理
总结Put过程:
- private 要是没放东西,放入 private
- 否则,准备放入 poolChain
- 如果 poolChain 中 的 Head 没创建,创建一个 HEAD, 然后创建容量为 8的 ring buffer ,把数据丢进去
- 如果 PoolChain 的ring buffer 没满,就放入
- 如果 poolChain Head 指向的ringBuffer 满了,创建一个新的节点,并且创建一个 两倍容量的ring Buffer ,数据丢去
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
// poolChain是一个动态大小的poolDequeue版本。
//
// 这被实现为一个双链接的poolDequeue的列表队列。
// 其中每个队列的大小是前一个队列的两倍。一旦一个
// 一旦一个dequeue满了,它就会分配一个新的dequeue,并且只推送到
// 最新的队列。推送从列表的另一端发生,并且
// 一旦一个dequeue被用完,它就会从列表中被移除。
type poolChain struct {
// head是要推送到的poolDequeue。它只被生产者访问
// 由生产者访问,所以不需要被同步。
head *poolChainElt
// tail是popTail的poolDequeue。这是由消费者访问的
// 被消费者访问,所以读和写必须是原子的。
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
// 下一个和上一个链接到这个池链中相邻的池链Elt。
// poolChain。
//
// next由生产者原子式写入,prev由消费者原子式读取。
// 而消费者则以原子方式读取。它只从nil过渡到
//非nil。
//
//prev,生产者以原子方式读出//prev。
// 而生产者则以原子方式读取。它只从
// 非零到零。
next, prev *poolChainElt
}
|
拿不到别人的 对象才去找 victim 里面的对象,其目的就是尽量的让 victim 里面的对象被垃圾回收。
进一步优化 Pool
大多数情况 pool可以直接使用,但是一个buffer 如果占据过多内存,要不要返回去? GC是比较不可控的。
- 控制单个buffer上限
- 控制buffer数量
- 控制总体内存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
type CustomPool struct {
p sync.Pool
maxcnt int32
cnt int32
}
func (p *CustomPool) Get() any {
return p.p.Get()
}
func (p *CustomPool) Put(val any) {
if unsafe.Sizeof(val) > 1024 {
return
}
/*
这种依赖于 GC 所以 cnt 是不可靠的
now := atomic.AddInt32(&p.cnt, 1)
if now >= p.maxcnt {
atomic.AddInt32(&p.cnt, -1)
return
}
*/
p.p.Put(val)
}
|
开源的 bytebufferPool框架
我们搞 buffer 缓存,就是希望这些
buffer 的 size 最好是恰好符合我们希
望的。过小会扩容,过大会浪费内
存。
所以 bytebufferpool 就根据使用次数
来决定:
参考文章
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// 把通过Get获得的字节缓冲区放到池子里,//返回池子后不能再访问缓冲区。
func (p *Pool) Put(b *ByteBuffer) {
idx := index(len(b.B))
if atomic.AddUint64(&p.calls[idx], 1) > calibrateCallsThreshold {
//超过阈值开始校验
p.calibrate()
}
maxSize := int(atomic.LoadUint64(&p.maxSize))
//大于maxsize 不缓存
if maxSize == 0 || cap(b.B) <= maxSize {
b.Reset()
p.pool.Put(b)
}
}
|
WaitGroup
WaitGroup 用于同步多个 goroutine工作
- 在开启 goroutine之前+1
- 每个小任务完成-1
- 调用 Wait 等待所有任务完成
WaitGroup:
- state1: 64位下, 高32位 记录了多少任务在运行;低32位记录了多少goroutine在等 wait方法返回
- state2: 信号量,用于挂起或者唤醒goroutine,约等于 Mutex里面的 sema字段 (注意很像对比)
1
2
3
4
5
6
7
|
wg := sync.WaitGroup{}
for i:=0;i<10;i++ {
wg.Add(1)
go func() { wg.Done() }
}
wg.Wait()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
// 一个WaitGroup等待一个goroutine的集合完成。
// 主程序调用Add来设置等待的goroutine的数量。
// 要等待的goroutines的数量。然后每个goroutine
// 运行并在完成后调用Done。同时。
// 可以用Wait来阻断,直到所有的goroutines都完成。
//
// 一个WaitGroup在第一次使用后不能被复制。
type WaitGroup struct {
noCopy noCopy
// 64位值:高32位是计数器,低32位是等待器计数。
// 64位原子操作需要64位对齐,但32位
// 编译器只保证64位字段是32位对齐的。
// 由于这个原因,在32位架构上我们需要在state()中检查
// state1是否对齐,并在需要时动态地 "交换 "字段的顺序。
//需要的话,动态地 "交换 "字段顺序。
state1 uint64
state2 uint32
}
// Done将WaitGroup计数器递减1。
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
func (wg *WaitGroup) Add(delta int) {
statep, semap := wg.state()
if race.Enabled {
_ = *statep // trigger nil deref early
if delta < 0 {
//与Wait同步进行递减。
race.ReleaseMerge(unsafe.Pointer(wg))
}
race.Disable()
defer race.Enable()
}
state := atomic.AddUint64(statep, uint64(delta)<<32)
// 等待数量
v := int32(state >> 32) //counter
w := uint32(state) //waiters , 这里 uint64 -> uint32 , 高位被丢弃了,相当于 就是 低 32位
if race.Enabled && delta > 0 && v == int32(delta) {
// 第一个增量必须与Wait同步。
// 需要将其建模为读,因为可能会有
// 几个并发的wg.counter从0开始的转换。
race.Read(unsafe.Pointer(semap))
}
if v < 0 { // 等待线程数量小于0
panic("sync: negative WaitGroup counter")
}
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
if v > 0 || w == 0 {
return
}
// 当waiters > 0时,这个goroutine已经将计数器设置为0。
// 现在不能再有并发的状态突变了。
// - 加法不能与Wait同时发生。
// - 如果Wait看到counter == 0,它就不会增加waiters。
// 仍然做一个廉价的理智检查来检测WaitGroup的误用。
if *statep != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// 将等待者计数重置为0。
*statep = 0
for ; w != 0; w-- { //唤醒 goroutine
runtime_Semrelease(semap, false, 0)
}
}
|
- noCopy: 用来告诉编译器 这个东西不能复制。 在sync 包里面很多结构体很多字段。我们也可以使用,比如 Dubbo-go 的 URL 结构体里使用了这个技巧
Go中没有原生的禁止拷贝的方式,所以如果有的结构体,你希望使用者无法拷贝,只能指针传递保证全局唯一的话,可以这么干,定义 一个结构体叫 noCopy ,要实现 sync.Locker 这个接口
我们使用 下面方法检测
1
|
go vet -copylocks -json
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
//等待块,直到WaitGroup计数器为零。
func (wg *WaitGroup) Wait() {
statep, semap := wg.state()
if race.Enabled {
_ = *statep // trigger nil deref early
race.Disable()
}
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32)
w := uint32(state)
if v == 0 {
//计数器为0,不需要等待。
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(wg))
}
return
}
// 递增等待者的数量。
if atomic.CompareAndSwapUint64(statep, state, state+1) {
if race.Enabled && w == 0 {
// 等待必须与第一个Add同步。
// 需要将此作为一个写的模型,以便与Add中的读进行竞争。
// 因此,只能对第一个等待者进行写操作。
// 否则,并发的Wait会互相竞争。
race.Write(unsafe.Pointer(semap))
}
runtime_Semacquire(semap)
if *statep != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(wg))
}
return
}
}
}
|
为什么两个计数器要合并
考虑一下为什么要煞费苦心将 counter 和 waiter 这两个计数合并成一个 uint64 类型的值?似乎可以用两个 uint32 的值来分开表示,然后在操作各自的时候都使用 uint32 的原子操作即可,这样也不用考虑内存对齐的问题。
这样做是因为 counter 和 waiter 这两个计数在使用时需要匹配才行,如果将这两个计数分开表示,那么就要用两次原子操作读取,在这两次原子操作之间就可能产生一些变化使 counter 和 waiter 不再匹配,从而导致一些难以预料的问题。
源码要点
| 字段 |
含义 |
| state1 |
高32位记录任务数量, 低32 记录等待数量 |
| state2 |
state2 表示sema信号量,原语 |
调用 wait , 低32位+1, 调用 Add(1), 高32位+1
如何协调 gorutine之间的工作,waitGroup 是可以的
- waitGroup 里面的wait 是如何做到
- Wait 是如何做到的? 核心是借助于 state2字段,利用了 runtime_Semaquire 和 runtime_Semrelease 两个调用。强调了Mutex类似机制
信号量上锁源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// state2 其实就是 信号量, semap 是 state2 的指针
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
if unsafe.Alignof(wg.state1) == 8 || uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
// state1 is 64-bit aligned: nothing to do.
return &wg.state1, &wg.state2
} else {
// state1 is 32-bit aligned but not 64-bit aligned: this means that
// (&state1)+4 is 64-bit aligned.
state := (*[3]uint32)(unsafe.Pointer(&wg.state1))
return (*uint64)(unsafe.Pointer(&state[1])), &state[0]
}
}
// 下面是 Add 方法部分解读
func (wg *WaitGroup) Add(delta int) {
/*中间省略 其他代码 */
//仍然做一个廉价的理智检查以检测WaitGroup的滥用。
if *statep != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// Reset waiters count to 0.
*statep = 0
for ; w != 0; w-- { // 释放 锁
runtime_Semrelease(semap, false, 0)
}
|
channel 编程– 发布订阅模式
- 不带缓冲:要求收发两端都必须要有 goroutine,否则就是阻塞。
- 带缓冲:没满或者没空之前都不会阻塞。但是满了
或者空了就会阻塞。
利用 channel 的思路
- 看做是队列,主要用于传递数据
- 利用阻塞特性,可以间接控制住 goroutine 或者
其它资源的消耗。这种用法有点像是令牌机制。
那么往 channel 里面读或者取一个数据,就有点
像是拿到一个令牌,拿到令牌才可以做某件事
实现细节
设计这样的 chan 结构体有什么问题要考虑:
- 要设计缓冲来存储数据。无缓冲=缓冲容量为0
- 要能阻塞 goroutine,也要能唤醒 goroutine。这个基本依赖于 Go 的运行时:
- 发数据唤醒收数据的
- 收数据的唤醒发数据的
- 要维持住 goroutine 的等待队列,并且是收和发两个队列
内存逃逸问题
内存分配:
- 分配到栈上:不需要考虑 GC
- 分配到堆上:需要考虑 GC
很不幸的,如果用 channel 发送指针,那么必然逃逸。
编译器无法确定,发送的指针数据最终会被哪个 goroutine
接收!
goroutine泄露问题
如果 channel 使用不当,就会导致 goroutine 泄
露:
- 只发送不接收,那么发送者一直阻塞,会导致发
送者 goroutine 泄露
- 只接收不发送,那么接收者一直阻塞,会导致接
收者 goroutine 泄露
- 读写 nil 都会导致 goroutine 泄露
基本上可以说,goroutine 泄露都是因为 goroutine
被阻塞之后没有人唤醒它导致的。
唯一的例外是业务层面上 goroutine 长时间运行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
type hchan struct {
qcount uint //队列中的总数据
dataqsiz uint // 循环队列的大小
buf unsafe.Pointer// 指向一个dataqsiz元素的数组
elemsize uint16
closed uint32
elemtype *_type // 元素类型
sendx uint // 发送索引
recvx uint // receive index
recvq waitq // 接受者 等待队列
sendq waitq // 发送者等待队列
// 锁定保护hchan中的所有字段,以及几个
// 在这个通道上被封锁的sudogs的几个字段。
//
// 在持有这个锁的时候,不要改变另一个G的状态。
// 特别是,不要准备好一个G),因为这可能会导致死锁
// 滞留在堆栈中。
lock mutex
}
|
channel源码解析
chansend 源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
|
/*
* 通用的单通道发送/转发
* 如果块不为零。
* 那么该协议将不会
* 睡眠,但如果它不能
* 不能完成。
*
* 睡眠可以在g.param == nil时唤醒
* 当参与睡眠的通道被关闭时
* 最简单的做法是循环并重新运行
* 操作;我们会看到它现在已经关闭了。
*/
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if c == nil { //nil 的channel 直接阻塞,而且无法被唤醒
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
if debugChan {
print("chansend: chan=", c, "\n")
}
if raceenabled {
racereadpc(c.raceaddr(), callerpc, abi.FuncPCABIInternal(chansend))
}
// 快速路径:检查失败的非阻塞操作,而不获取锁。
//
// 在观察到通道没有关闭后,我们观察到通道没有准备好发送。每个观察结果都是一个字大小的读数
//(第一个c.closed和第二个full())。
// Because a closed channel cannot transition from 'ready for sending' to
// 'not ready for sending', even if the channel is closed between the two observations,
// they imply a moment between the two when the channel was both not yet closed
// and not ready for sending. We behave as if we observed the channel at that moment,
// and report that the send cannot proceed.
//
// It is okay if the reads are reordered here: if we observe that the channel is not
// ready for sending and then observe that it is not closed, that implies that the
// channel wasn't closed during the first observation. However, nothing here
// guarantees forward progress. We rely on the side effects of lock release in
// chanrecv() and closechan() to update this thread's view of c.closed and full().
if !block && c.closed == 0 && full(c) {
return false
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// 信道缓冲区内有空间。对要发送的元素进行排队。
//接受者在这里阻塞等待数据
if sg := c.recvq.dequeue(); sg != nil {
// 找到了一个等待的接收器。我们将我们要发送的值
//直接传递给接收者,绕过通道缓冲区(如果有的话)。
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
if c.qcount < c.dataqsiz { //* 没有接受者,准备丢缓存
// 信道缓冲区内有空间。对要发送的元素进行排队。
qp := chanbuf(c, c.sendx)
if raceenabled {
racenotify(c, c.sendx, nil)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
if !block {
unlock(&c.lock)
return false
}
// Block on the channel. Some receiver will complete our operation for us.
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// 在分配elem和排队等待mysg之间没有堆栈分裂,
//在gp.waiting上,copystack可以找到它。
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg)
// 向任何试图缩减我们的堆栈的人发出信号,我们即将停在一个通道上。从这个G的状态发生变化
//到我们设置gp.activeStackChans之间的窗口对于
//缩减堆栈是不安全的。
atomic.Store8(&gp.parkingOnChan, 1)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
// 确保正在发送的值保持活力,直到
//接收者将其复制出来。sudog有一个指向
//堆栈对象的指针,但sudog不被认为是堆栈跟踪器的根。
//* 确保 ep 不会被垃圾回收
KeepAlive(ep)
// 有人叫醒了我们。
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
closed := !mysg.success
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
releaseSudog(mysg)
if closed {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
return true
}
|
- KeepAlive 确保 ep 不会垃圾回收掉
- 实际上就是确保,发送的数据不会被垃圾回收掉
- 一般是和 SetFinalizer 结合使用
- 个人建议不要用
chanrecv 源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
|
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// raceenabled: 不需要检查ep,因为它总是在堆栈上。
// 或者是由反射分配的新内存。
if debugChan {
print("chanrecv: chan=", c, "\n")
}
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// Fast path: check for failed non-blocking operation without acquiring the lock.
if !block && empty(c) {
// 在观察到通道没有准备好接收后,我们观察通道是否
// 通道是否关闭。
//
// 这些检查的重新排序可能导致在与关闭的比赛中出现不正确的行为。
// 例如,如果通道是开放的并且不是空的,被关闭,然后排空。
// 重新排序的读取可能会错误地显示 "开放和空"。为了防止重新排序。
// 我们在这两个检查中使用原子加载,并依靠清空和关闭发生在
// 在同一个锁下的单独的关键部分发生。 这个假设在关闭
// 的无缓冲通道,但这也是一个错误条件。
if atomic.Load(&c.closed) == 0 {
// 因为一个通道不能被重新打开,所以后来观察到的该通道
// 暗示它在第一次观察的时候也没有关闭。
// 第一次观察时也没有关闭。我们的行为就像我们在那一刻观察到了这个通道一样
// 并报告说接收不能继续。
return
}
// 该通道被不可逆转地关闭。重新检查该通道是否有任何待接收的数据
// 来接收,这些数据可能是在上面的空和关闭检查之间到达的。 在与这样的发送比赛时,
//这里也需要顺序一致性。
if empty(c) {
// The channel is irreversibly closed and empty.
if raceenabled {
raceacquire(c.raceaddr())
}
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
// 有接受者可以获取
if sg := c.sendq.dequeue(); sg != nil { // 有人等着发送,直接收数据
// 找到了一个等待的发件人。如果缓冲区大小为0,则接收值
// 直接从发送方接收。否则,从队列的头部接收
// 并将发送者的值添加到队列的尾部(两者都映射到
//同一个缓冲区槽,因为队列已经满了)。
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
if c.qcount > 0 {
// Receive directly from queue
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
}
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}
// no sender available: block on this channel.
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// 在分配elem和排队等待mysg之间没有堆栈的分裂。
//在gp.waiting上,copystack可以找到它。
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
//向任何试图缩小我们堆栈的人发出信号,我们即将
//要停在一个通道上。从这个G的状态发生变化到我们设置gp.activeStackChans之间的窗口
// 变化和我们设置gp.activeStackChans之间的时间段,对于堆栈收缩来说是不安全的。
// 缩减堆栈。
atomic.Store8(&gp.parkingOnChan, 1)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
// someone woke us up
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, success
}
|
chanrecv 步骤
- 看是不是 niL channel, 是的话直接阻塞
- 看有没有被阻塞的发送者,有的话直接从发送者手里拿,反馈
- 看看缓冲有没有数据,有就读缓存,返回
- 阻塞,等待发送者唤醒自己
- 被唤醒,做清理工作
面试要点
- channel 有buffer和没有buffer区别
- 发送数据都nil channel hi怎么样? 发送到已关闭的channel会怎么样
- 从 nil channel 及饿哦书数据会怎么样? 从已关闭的channel接收数据会怎么样?
- channel怎么引发goroutine 泄露? 泄露原因有哪些?
- channel发送步骤
- channel 接收步骤
- 为什么channel发送指针数据会引起内存泄露
- 可能的代码题:
- channel实现任务池
- 控制 goroutine数量
- 用channel实现生产者-消费者模型
实现任务池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
type TaskPool struct {
ch chan struct{}
}
func NewLimit(n int) *TaskPool {
t := &TaskPool{
ch: make(chan struct{}, n),
}
for i := 0; i < n; i++ {
t.ch <- struct{}{}
}
return t
}
func (t *TaskPool) Do(f func()) {
token := <-t.ch
defer func() {
t.ch <- token
}()
f()
}
func main() {
p := NewLimit(10)
var ptr int64
for i := 0; i < 1000; i++ {
p.Do(func() {
u := atomic.AddInt64(&ptr, 1)
fmt.Println(u)
})
}
}
|
实战练习
假设我们现在有一个 Web 服务。这个 Web 服务会监听两个端口:8080 和 8081。其中 8080 是用于监听正常的业务请求,它会被暴露在外部网络中;而 8081 用于监听我们开发者的内部管理请求,只在内部使用。
同时为了性能,我们在该服务中使用了本地缓存,并且采用了 write-back 的缓存模式。这个缓存模式要求,缓存在 key 过期的时候才将新值持久化到数据库中。这意味着在应用关闭的时候,我们必须将所有的 key 对应的数据都刷新到数据库中,否则会存在数据丢失的风险。
为了给用户更好的体验,我们希望你设计一个优雅退出的步骤,它需要完成:
- 监听系统信号,当收到 ctrl + C 的时候,应用要立刻拒绝新的请求;
- 应用需要等待已经接收的请求被正常处理完成;
- 应用关闭 8080 和 8081 两个服务器;
- 我们能够注册一个退出的回调,在该回调内将缓存中的数据回写到数据库中。

