
内存管理

文章目录
内存管理知识
RAM (random access memory)
- 随机存储器中数据的读写可以在几乎相同的时间内完成,与树物理位置无关
分层存储体系 (memory hierarchy)
- 硬盘
- 内存
- L3 (<=100mb)
- L2 (<=20Mb)
- L1 <1m
- CPU
通常我们说的内存 包括CPU 和缓存 也被称为内存
- L1 2-4 cycle
- L2 10-20 cycle
- L3 20-60 cycle
- RAM 200-300 cycle
- HD (RW :10-50m cycle), 硬盘 hard disk
- SSD ~ 内存的10-1000倍
这些数值代表 读取数据的周期,周期越短,速度越快
进程间内存如何隔离
多进程如何复用2个寄存器
- 进程表中存储了所有用到的寄存器
虚拟内存、页表和 MMU
- 只有 32KB内存,如何抽象出64kb内存让进程使用?
- 将内存切成很多小块,进程使用离散小块
- 解决进程轮流使用内存 (swapping 小块)
虚拟地址空间
程序运行在虚拟地址空间,遇到内存地址就映射物理空间
:(page,offset) = (frame,offset)
页表项结构
(高速缓存禁止位,访问位,修改位,保护位,【在不在】 位,Frame)
- 高速缓存禁止位: 允不允许L1、L2、L3等高速缓存缓存页框
- 访问位,有没有被读过
- 修改为: 有没有写过 (dirty)
- 保护位: 可不可以写入
- [在不在]位置: 对应的Frame目前在不在内存中
- Frame 是代表指向的内存中的区域
内存管理单元(Memory Management unit)
- MMU 位于CPU内部,可以通过硬件电路完成内存映射
比如 MOV R0 10000
把内存地址10000的值 存到 R0寄存器,这个10000是个虚拟地址,不是真实的物理地址,计算机通过MMU 将计算出真实的物理地址再进行操作
MMU 如何工作的
-
虚拟地址通过MMU映射为 物理地址
-
0-1 代表的是存在火灾不存在,如虚拟地址页号指向一个不存在的 frame,那么会触发操作系统的缺页中断。
-
操作系统告诉MMU页表在内存中的位置->MMU加载页表-> MMU 利用页表进行地址转换
-
CPU对MMU 对页表中条目数量大小有限制,有的会有几个M,也可能更大
-
操作系统内核中有负责MMU管理模块
缺页中断是什么?
多级页表
- MMU 先用 PT1 在顶级页表查询2级页表在内存中的位置
- MMU利用 PT2 在二级页表中查 frame位置
- MMU 根据 Frame的值将虚拟内存地址映射为物理内存地址
其他问题:
- 使用多级页表,比如3级,4级,会增加MMU的计算次数
快表结构
- 快表,小型硬件设备- 也叫转换检测缓冲区(translation lookaside buffer),用来加速MMU读写
第一次通过计算地址,访问某块内存,直接缓存这个地址,下次直接跳到这个地址。
内存回收
java,golang 和 node是怎么做的?
最开始堆内存管理的方式是 维持一条双向链表,给程序分配内存计算在这个链表上面分配内存
其他的方法,也有用数组+ 链表的,
后面的做法 其实是 通过缓存 来记录页表
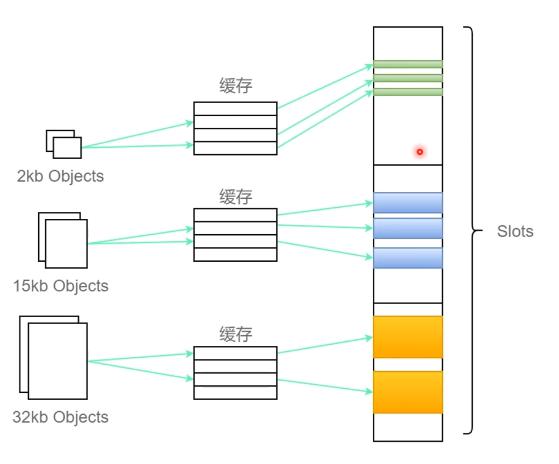
程序语言是否也用 slot法管理内存?
- 部分没有虚拟机的语言,创建对象是创建在cache-slot上,比如c 的malloc就是直接分配一个合适大小的cache
- 还有一些有虚拟机的语言,有自己的内存管理
- 另一方面,程序 语言不需要像操作系统一样预留大量类型 的是 slot 等待分配(因为程序大小不一,功能不一样)
垃圾回收算法
-
引用计数法
- 扫描引用
- 维护引用
-
可达性分析算法
- gc的场景
- 内存反复被利用的场景
- 大量对象在被分配和回收
- 高并发场景
- gc的场景
gc的种类
STW (stop the world) 模型
Increment Update 模型
这2个模型都需要 mark 标记,第一个 mark 是要进行 全局标记,这样就可能会比较长的时间停顿, 第二个模型是分时间 一点点的 mark ,这样停顿时间就可以缩短了。
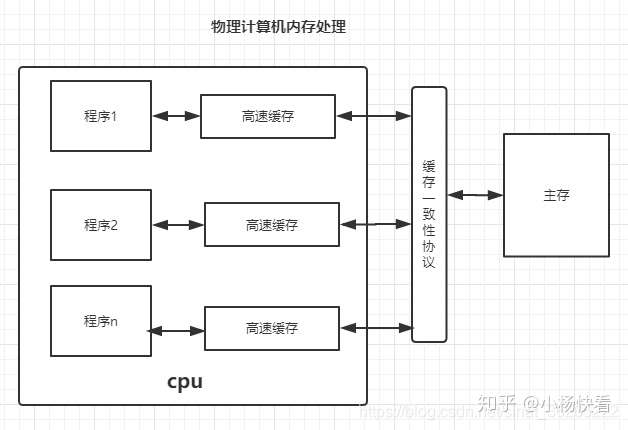
stop the world 问题
-
思考: mark阶段需不需要终止正在运行的程序:
- 新增一个对象,需不需要 mark
- 删除一个对象需不需要重新 mark
-
思考: 如何可以不 stw ?
- 做不到,可以考虑缩短 stw的时间,让用户感知是一个连续的模型
三色标记(tri-color mark)
- go和 node 在用
- 属于 increment upate 模型 – 解决stw问题
过程:
- 白色: 需要回收
- 黑色:不回收
- 灰色: 中间地带
灰->黑
- 以灰色节点为开始点,做一次bfs,之前灰色节点标黑色,剩下的白色节点就需要回收
思考: 会不会有mutation违反性质
-
比如读白色节点的mutation
-
改变黑色节点的 mutation
-
方法:
- 读取白色节点的时候增加读屏障(read barrier),禁止读取
- 改变黑色节点的时候增加写屏障(write barrier),写入结束后,将这个节点标记为灰色。 (变灰后又要重新标记)
-
严格保证了所有黑色节点指向白色节点。
- 如果黑色节点使用了白色节点的内存,那么白色节点要被回收,这样就有问题了。
要保证正确性,就要保证黑色不指向白色,因此可以让每次灰色节点的遍历标记都打入更小的时间片段
如果 mutation过多? ,gc 每次回收不完全会发生什么?
分代收集
编程的时候,很多对象都是刚创建,用一下就可以被回收了,这种对象会频繁的被回收,只有少部分会活的比较就,因此有必要对对象做分代收集, go语言 目前好像是没有分代收集的实现,这里参考java的实现。
-
新生代 => 复制算法
- eden
- s0
- s2
-
老年代 (Tenured) => cms
-
永久代 permanent(元空间)
文章作者 lyr
上次更新 2022-05-11