
文件系统,inode

文章目录
文件系统
定义
文件系统是指操作系统用于明确存储设备或分区上的文件的方法和数据结构,即在存储设备上组织文件的方法;操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统;文件系统负责为用户建立文件,存入、读出、修改、转储文件等。
文件系统的实现
-
两种文件系统
- 磁盘文件系统
- 内存文件系统
-
磁盘文件系统结构
- 引导控制块 (boot control block),包含系统引导操作系统的各种信息,只有安装操作系统的分区才有
- UFS: 引导块(boot block)
- NTFS: 分区引导扇区(partition boot sector)
- 分区控制块 (partition control block)
- 总的块数、空闲块数、块大小等信息
- UFS: 超级块 (superblock)
- NTFS: 主控文件表(master file table)
- 引导控制块 (boot control block),包含系统引导操作系统的各种信息,只有安装操作系统的分区才有
理解
- 什么是文件系统
- 如何使用文件系统
- 本地文件系统的原理
- ext3
- xfs
- Ext2源代码解析
- 网络文件系统介绍
- 本地文件系统通过网络搬到另一台服务器上
- 文件系统数据的共享【只有一台存储节点】
- 分布式文件系统介绍
- 服务端通过集群的方式实习存储系统,对外提供统一的命名空间
- 对象存储介绍
- 文件系统存储的一种简化形态
文件系统的种类
Filesystem hierarchy standard
| 目录 | 介绍 |
|---|---|
| bin | 必备的用户目录,ls,cp等 |
| sbin | 必备的系统管理员目录,ifconfig,reboot |
| dev | 设备文件,例如 mtblock0,tty1等 |
| etc | 系统配置文件,启动文件等 |
| lib | 必要的链接库,例如内核模块,c链接库 |
| home | 普通用户主目录 |
| root | root用户主目录 |
| usr/bin | 非必备用户程序,find,du等 |
| usr/sbin | 非必备的管理员程序,chroot,inetd等 |
| usr/lib | 库文件 |
| var | 守护程序和工具程序存放的可变,例如日志文件 |
| proc | 用户提供内核与进程信息的虚拟文件系统,内核自动产生 |
| sys | 提供内核与设备信息的虚拟文件系统,内核自动生成 |
| mnt | 文件系统挂接点,用于临时安装文件系统 |
| tmp | 临时文件,重启后自动删除 |
busybox文件系统
inode源码
|
|
[[post/14.新语言学习记录/linux/linux基础原理杂记/linux_inode原理 | vfs文件系统原理等]]
linux 文件系统生态
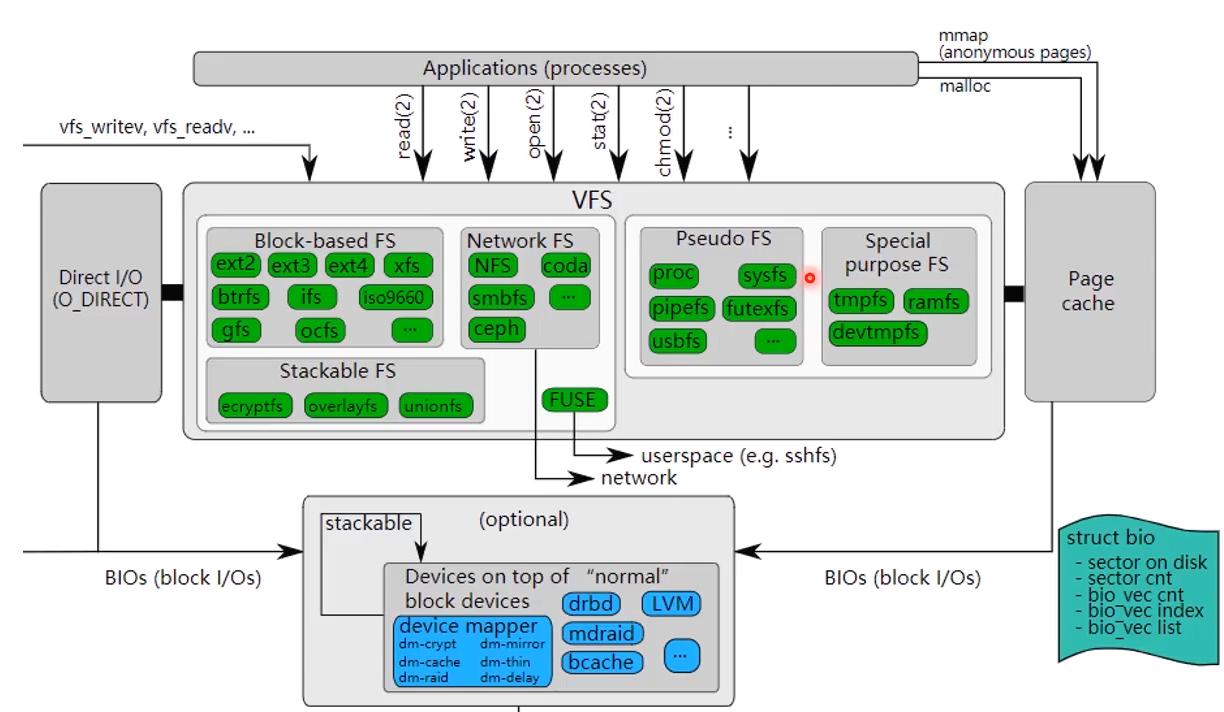
文件系统是一种抽象机制,通过给存储在磁盘的数据每个起一个名字,每个叫做一个文件,提供了根据文件名来操作这些信息的方法(读、写、修改等)。
- 如 Linux的文件 /opt/data/a.dat
- /opt/data 是文件的目录
- a.dat 是文件名字,.dat 是扩展名
一些常见的文件系统
- FAT (file allocate table ,文件分配表)
- FAT16、FAT32
- Ext2 (second extended file system)
- Ext3 (third extended file system)
- NTFS (NT File System)
硬盘
需要了解的概念:
磁盘: 用于存储大量数据的永久性存储器(不会断电消失,操作系统首先是装在磁盘里的)
硬盘的组成:
- 磁道 (Track)
- 柱面 (Sylinder) ,一个圆柱体的结构
- 扇区 (Sector) , 硬盘存储数据的最小单位,一些硬盘是 512 byte,
- 簇 (cluster),
固态硬盘(SSD)
- 固态硬盘使用集成电路读数据进行永久存储
- 控制器(controller) 用来寻址
- 存储芯片(一般是闪存)
由于硬盘的物理结构不一样,操作系统需要对磁盘做底层的抽象,可以理解为 物理块
- 物理块是操作系统对磁盘最底层的抽象,目前最多使用的是 4kb的块
- 支持读写
日志文件系统: mysql 备份的时候记录的是数据变化的过程,而不是数据变化最后的结果, 这就是日志文件系统
空闲物理块
基于链表的空闲管理(类比基于链表的内存管理)
注意: 这个链表是反复出现的,之前 我在内存管理那篇文章 就有写过一个基于链表的内存管理的方法 ,[[post/14.新语言学习记录/linux/linux基础原理杂记/linux内核理解/内存管理.md | 内存管理]]
两种方式:
- 基于链表的空闲管理(类比基于链表的内存管理)
- 基于位图的空闲块管理
- fat方法
- index-node 方法
使用链表分配会浪费很多空间,后面又有了Fat的方式进行分配。
文件分配表会耗费大量的内存
$ 1T = 20^{30}k$
$ 1T/4k * 4bytes=2^{30}/4*4bytes=1G$
1T的存储 需要 用 1G的空间,这种会浪费大量的空间。
内存中的inode表
inode 是存储在磁盘上的,只有打开文件,才会把inode 加载到内存中。
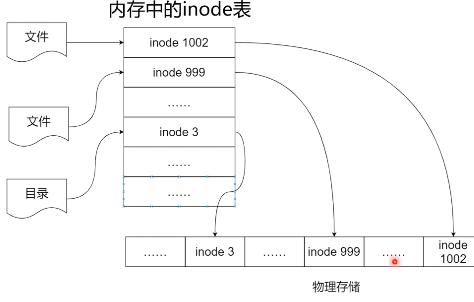
inode 是如何存储大文件的?
inode 使用 树状结构, 如果 一个索引块存不下,就使用二级间接索引块,二级存不下,就使用三级间接块
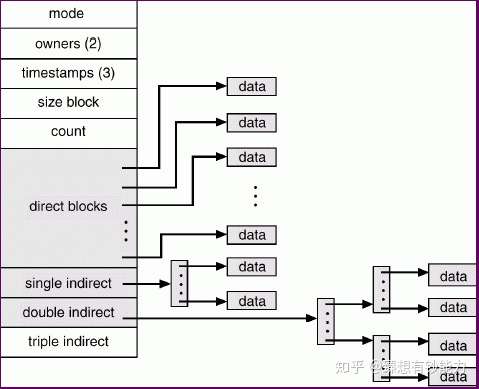
如图所示,分为直接块和间接块,间接块使用树状存储,保证了搜索的高效性【树的查找速度和其高度有关】
比如 $2^{100}$ 的个数,被树二分后,我们只需要查找 100 次,这样是非常快的
寻找 /user/local/a.txt 的过程
这里的效率 肯定不搞, 假设某个文件夹下面有100万个文件或者 文件夹,这样遍历这个inode效率太低了,所以 可以使用 hash table 加速文件查询
硬链接和软连接的区别
硬链接是直接引用的 inode, 软连接则是存储文件路径的文件名
硬连接是多个文件指向同一个inode,删除的时候要看inode的引用计数。而且inode 得真实存在
软连接两个文件有不同的inode,但是文件A 的 inode 很小,只存储文件B的文件名字
虚拟文件系统标准(virtual File System)
比如说我设计一个数据库,我就需要自己实现一个文件系统,操作系统自带的文件系统可能无法满足我的要求。 只要满足虚拟文件系统的要求,就能被虚拟文件系统使用。
高速缓冲区
- 类似CPU的缓存、内存管理的快表– 频繁使用的文件内容被缓存
- 思考: 高速缓冲区为什么要统一由虚拟文件系统(vfs)提供
如果你删除文件的时候突然断点了,会发生什么?
- 删除文件A 的过程描述
- 更新A所在的目录
- 释放A的inode
- 释放A占用的物理块(将物理块加入空闲列表、位图)
如果没有释放 A的物理块,这样就很危险了。
于是人们提出 基于 日志的文件管理的做法
故障恢复
如果删除文件的时候,突然断点了,系统记录到了关机异常状态,于是就会重新执行记录的日志内容,恢复操作
日志文件系统故障恢复的要求:
提出问题:
- 如果执行完了110号日志,但是突然关机,系统没有来得及记录下来的109号日志已经被执行了该怎么办?
- 保险起见:开机后从108号日志开始执行
- 要求:所有日志操作可以被重入(重复执行,幂等性)
- 例如:删除一个指定的 inode就是幂等操作
- 清理几个磁盘块也是幂等操作
mysql,redis 这些数据库都是基于日志的文件系统,很多分布式系统的文件系统都是基于日志的文件系统。
epoll,select,poll
- 场景: 有100w个socket连接需要处理
- 思考:
- linux下 socket连接抽象成了文件(100w个文件句柄)
- 系统其实就是在不断检查100w个文件 中有没有数据到来
- 100w个 socket并发很高,稍有不慎,就会造成系统雪崩
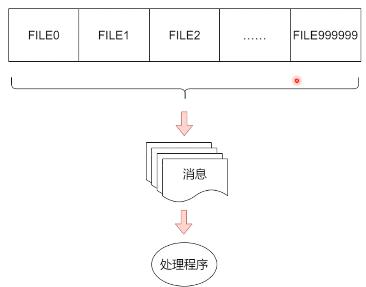
阻塞IO
|
|
不断的等待和循环 我们可以开启多线程 每个线程负责处理各种的sockets 数组所在的位置。
这种就是多线程 阻塞IO 的处理方式
多路复用
100w个线程处理100w个连接,切换成本大,100w个进程更不可能,我们可以让一个线程复用,处理多个 fd
|
|
- select/poll 模型是同步还是异步?
- select、poll 模型是阻塞还是非阻塞?
可以阻塞,也可以不阻塞, select 和 poll,epoll 全部都是同步 IO,异步IO的话 windows 下 iocp 才是
上面的 模型有问题,比如 我每次拷贝1000个fd到内核,这样就消耗太大了,所以可以用共享内存来优化。
优化fd 的 增加删除,查询
- 数组, insert ,o(N), find o(N),delete O(N)
- 链表, insert ,o(1), find (oN)
- hashtable, 效果不好
- 平衡树:
- insert o(logN)
- delete o(logN)
- find o(logN)
epoll 的解决方法
- 增量向内核传输 fd
- 内核返回 事件,而不是 fd
- 事件中带有可以被读取的 fd(避免线程遍历)
fat,ext2 数据结构
- 盘片(platter)
- 磁头(head)
- 磁道(track)
- 扇区(sector)
- 柱面(cylinder)
扇区、块/簇、page的关系
扇区: 硬盘的最小读写单元 块/簇: 是操作系统针对硬盘读写的最小单元 page: 是内存与操作系统之间操作的最小单元。 扇区 <= 块/簇 <= page
raid 原理
简介 一种冗余技术,保障了数据的可靠性,将同一份数据复制到两块磁盘中,在一块磁盘损坏后,另一块镜像磁盘可以继续工作,确保了外部系统能够正常访问数据,从而保证系统运行,同时在读取数据时可以同时从两块硬盘中并行读取数据,从而提高了数据读的 I/O 性能,但是多块硬盘的数据写入降低了写的 I/O 性能。
优点: 一方面提高可靠性,另一方面,并发的从两个或多个副本中读取数据,可以提高读性能。
缺点: 相同数据需要同时写入多个磁盘,磁盘的写性能低。
文章作者 lyr
上次更新 2022-04-05