awk学习
awk语法
1
2
3
4
|
Usage: awk [POSIX or GNU style options] -f progfile [--] file ...
awk '{ sum += $1 }; END { print sum }' file
# 可以直接 man 1 awk 查看内容
|
1
2
|
awk '{print $1}' temp
# 输出每一行的第一列单词,以空格区分单词
|
参数
| 参数代码 |
解释 |
$0 |
表示整行 |
$num |
表示 第 num 列 |
$NF |
表示当前分割后的最后一列 |
| FS |
字段分割符 ,可以 -F 指定内容,默认 -F" " ,输入分隔符 |
| OFS |
输出分隔符,又叫,output field separator |
| RS |
输入记录分割符(输入换行符),指定输入时换行符 |
| ORS |
输出记录分隔符,输出换行符 |
| NF |
number of field ,行字段个数 |
| FNR |
各文件分别计数的行号 |
| ARGC |
命令行参数的个数 |
| ARGV |
数组,保存命令行给定的各参数 |
练习
打印第五行
1
2
|
cat temp -n | awk -F" " 'NR==5'
cat temp -cat temp -n | awk -F" " '{ if (NR == 5) {print $0 } }'
|
实现 cat -n
1
|
awk '{print NR" "$0}' temp
|
打印第一列和倒数第一列
1
|
awk '{print $1 , $(NF-1)}' temp
|
打印2-4行
1
|
awk 'NR==2,NR==4{print $0}' temp
|
指定分隔符
1
|
cat /etc/passwd | awk 'BEGIN{ FS=":" } {print $1}'; echo "---------- xx -----------" ; cat /etc/passwd | awk -F ":" '{print $1}'
|
取出ip地址信息
1
2
3
|
ifconfig | awk 'NR==2 {print $2}'
ifconfig | awk '$1=="inet" {print $2}'
# 第一列 是 inet 的,就答应 inet后面的 ip信息
|
leetcode 词频率统计
leetcode 词频率统计
1
2
3
4
5
6
7
|
the day is sunny the the
the sunny is is
the 4
is 3
sunny 2
day 1
|
1
2
|
awk '{ for (i=1;i<=NF;i++) res[$i]++ } END{for(k in res) print k,res[k] }' words.txt |
sort -nr -k2S
|
其他
cut 命令
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
参数:
- -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
- -c :以字符为单位进行分割。
- -d :自定义分隔符,默认为制表符。
- -f :与-d一起使用,指定显示哪个区域。
- -n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除
1
2
3
4
5
6
|
lyr@DESKTOP-FSVN6C0:~$ echo "hello world ttt" | cut -d " " -f1
hello
lyr@DESKTOP-FSVN6C0:~$ echo "hello world ttt" | cut -d " " -f2
world
lyr@DESKTOP-FSVN6C0:~$ echo "hello world ttt" | cut -d " " -f3
ttt
|
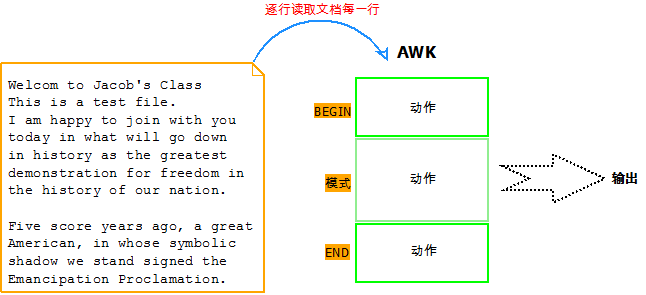
awk 命令
参考博客
参考博客2


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
# gawk -F: '{ print $1 }' /etc/passwd
lyr@DESKTOP-FSVN6C0:~$ echo "hello world ttt" | awk -F " " '{print $1}'
hello
lyr@DESKTOP-FSVN6C0:~$ echo "hello world ttt" | awk -F " " '{print $2}'
world
lyr@DESKTOP-FSVN6C0:~$ echo "hello world ttt" | awk -F " " '{print $3}'
ttt
lyr@DESKTOP-FSVN6C0:~$ echo "hello world ttt" | awk -F " " '{print $0}'
hello world ttt
lyr@DESKTOP-FSVN6C0:~$ echo "hello world ttt" | awk '{print NF}'
3
# 打印 每一行的字段个数
lyr@DESKTOP-FSVN6C0:~$ echo "hello world ttt" | awk '{print NF,NR}'
3 1
lyr@DESKTOP-FSVN6C0:~$ cat /etc/passwd | awk -F: '{print $1}'
root
daemon
bin
# -F 指定 : 为分隔符
cat /etc/passwd | awk 'BEGIN{FS=":"} {print $1}'
# 和 -F 一样, 这里叫做 File separator
# 指定行分隔符, 默认就是 \n 回车符
# 我想修改 换行的指定方式
lyr@DESKTOP-FSVN6C0:~$ awk 'BEGIN{FS=" ";RS="---"} {print $1}' text
hello
1
you
app.sh
lyr@DESKTOP-FSVN6C0:~$ cat text
hello world tt---1 2 3---you monther fuck---app.sh tt 111
# 这里 RS 指定 --- 为 换行符号
lyr@DESKTOP-FSVN6C0:~$ awk 'BEGIN{FS=" ";RS="---";ORS=":"} {print $1}' text
hello:1:you:app.sh:
lyr@DESKTOP-FSVN6C0:~$
# ORS output row seperator 输出符号
lyr@DESKTOP-FSVN6C0:~$ awk 'BEGIN{FS=" ";RS="---";ORS=":";OFS="%"} {print $1,$2}' text
hello%world:1%2:you%monther:app.sh%tt:
lyr@DESKTOP-FSVN6C0:~$
|
printf 格式化输出
- %s 打印字符串
- %d 打印十进制数
- %f 打印 一个 浮点数
- %x 打印十六进制数
- %o 八进制
- %e 科学计数
- $c ascii
- `- 左对齐
+ 右对齐# 八进制前面+ 0, 16进制的前面加 0x
一般前2种用的多
1
2
3
4
5
6
7
8
9
10
11
12
13
|
lyr@DESKTOP-FSVN6C0:~$ cat text | awk '{printf "%s\n", $1 }'
hello
lyr@DESKTOP-FSVN6C0:~$ cat text | awk '{printf "%s=%s\n", $1,$2 }'
hello=world
=
lyr@DESKTOP-FSVN6C0:~$ cat text | awk '{printf "%20s=%20s\n", $1,$2 }'
hello= world
=
# %20 占用 20个字符对齐
lyr@DESKTOP-FSVN6C0:~$ cat text | awk '{printf "%-20s=%-20s\n", $1,$2 }'
hello =world
=
# end
|
匹配模式
-
regExp
- 打印 yarn开头的行
cat text | awk 'BEGIN{}/^yarn/{printf "%s\n", $1 }' - 匹配 /etc/passwd 中第3个字段大于 50的 所有行信息 [ if筛选 ]
-
布尔运算
- &&
- ||
- !
-
关系运算
>= <===

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
lyr@DESKTOP-FSVN6C0:~$ cat text | awk 'BEGIN{}/^hello/{printf "%s\n", $1 }'
hello
# 打印 hello 开头的行
lyr@DESKTOP-FSVN6C0:~$ awk 'BEGIN{FS=":"}$3<=50 && $3>=0 {print $1,$3}' /etc/passwd
root 0
daemon 1
bin 2
sys 3
sync 4
games 5
man 6
lp 7
mail 8
news 9
uucp 10
proxy 13
www-data 33
backup 34
list 38
irc 39
gnats 41
lyr@DESKTOP-FSVN6C0:~$ awk 'BEGIN{FS=":"}$3<=150 && $3>=50 {print $1,$3}' /etc/passwd
systemd-network 100
systemd-resolve 101
systemd-timesync 102
messagebus 103
syslog 104
_apt 105
tss 106
uuidd 107
tcpdump 108
sshd 109
landscape 110
pollinate 111
# 另外一种写法
awk 'BEGIN{FS=":"}{if($3<50 || $3>100) print $0 }' /etc/passwd
# if else 写法
awk 'BEGIN{FS=":"}{if($3<50 ) { print $0;} else if($3>=100) { print $0 } }' /etc/passwd
# 写到一行 太难看了,可以 换行
lyr@DESKTOP-FSVN6C0:~$ awk 'BEGIN{FS=":"}{
if ( $3 < 50 ) { print $0 }
else if( $3 >100) { print $0 }
}' /etc/passwd
|
表达式赋值动作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
lyr@DESKTOP-FSVN6C0:~$ ./app.sh
hello 21
lyr@DESKTOP-FSVN6C0:~$ cat app.sh
awk 'BEGIN{w=20;num="hello";w++; print num,w}';
# 可以 w++ 自增
# 匹配空白行
lyr@DESKTOP-FSVN6C0:~$ awk '/^$/{idx++}END{ print idx}' ./app.sh
15
# 我看可以看到,有 15个空行
lyr@DESKTOP-FSVN6C0:~$ awk '/^#/{idx++;print $0 }END{ print idx}' ./app.sh
#!/bin/bash
#Author:LYR
#Time:2021-10-03 17:35:05
#Name:app.sh
4
# 这里 我们打印 # 开头的行
# 然后打印出 4 行结果
lyr@DESKTOP-FSVN6C0:~$ awk '/^#/{idx++;print idx,$0 }END{ print "----" , idx}' ./app.sh
1 #!/bin/bash
2 #Author:LYR
3 #Time:2021-10-03 17:35:05
4 #Name:app.sh
---- 4
|

if 和 else 赋值
1
2
3
4
|
lyr@DESKTOP-FSVN6C0:~$ awk 'BEGIN{FS=":"}{
if ( $3 < 50 && $3>=0 ) { print $0 }
else if( $3 >100) { print $0 }
}' /etc/passwd
|
将代码写入一个文件里面
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
lyr@DESKTOP-FSVN6C0:~$ cat test.sh
BEGIN{
FS=":"
}
{
if ($3<50)
{
print $0
}
}
END {
print "execute success"
}
lyr@DESKTOP-FSVN6C0:~$ awk -f ./test.sh /etc/passwd
root❌0:0:root:/root:/bin/bash
daemon❌1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin❌2:2:bin:/bin:/usr/sbin/nologin
sys❌3:3:sys:/dev:/usr/sbin/nologin
sync❌4:65534:sync:/bin:/bin/sync
games❌5:60:games:/usr/games:/usr/sbin/nologin
man❌6:12:man:/var/cache/man:/usr/sbin/nologin
lp❌7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail❌8:8:mail:/var/mail:/usr/sbin/nologin
news❌9:9:news:/var/spool/news:/usr/sbin/nologin
uucp❌10:10:uucp:/var/spool/uucp:/usr/sbin/nologin
proxy❌13:13:proxy:/bin:/usr/sbin/nologin
www-data❌33:33:www-data:/var/www:/usr/sbin/nologin
backup❌34:34:backup:/var/backups:/usr/sbin/nologin
list❌38:38:Mailing List Manager:/var/list:/usr/sbin/nologin
irc❌39:39:ircd:/var/run/ircd:/usr/sbin/nologin
gnats❌41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats:/usr/sbin/nologin
execute success
# 最后 我看可以看到 END 代码块也执行了
# awk -f 就是指定代码的脚本文件
|
我们推荐 将 awk 命令写到 一个 .awk 的脚本文件里面,方便我们以后 查看
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
vim student.awk
BEGIN{
printf "%-10s%-10s%-10s%-10s%-10s%-10s\n","Name","Chiness","English","Math","Physical","Average"
}
{
total=$2+$3+$4+$5
avg=total/4
if(avg>90)
{
printf "%-10s%-10d%-10d%-10d%-10d%-0.2f\n",$1,$2,$3,$4,$5,avg
# 累加各科分数
score_chinese+=$2
score_english+=$3
score_math+=$4
score_physical+=$5
}
}
END{
printf "%-10s%-10d%-10d%-10d%-10d\n","",score_chinese,score_english,score_math,score_physical
}
awk -f student.awk student.txt
|
awk 处理函数


计算 passwd 的字符的个数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
BEGIN{
FS=":"
}
{
i=1
while(i<=NF)
{
if(i==NF)
{
printf "%d",length($i)
}
else
{
printf "%d:",length($i)
}
i++
}
printf "\n"
}
|
将字符串转大写
1
2
3
4
5
6
7
|
BEGIN{
s="hello hadoop";
print toupper(s);
}
|
分割并打印
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
BEGIN{
s="hello hadoop";
split(s,arr," ")
print arr[2]
}
{
for (a in arr)
{
print arr[a]
}
}
|
awk 使用 数组,下标从1 开始 ,shell 下标从 0 开始计数
awk 其他选项
- -v 定义变量
- -f 指定目录脚本
- -F 分隔符
- -V 查看版本号
 次阅读
次阅读